21.11.2024
Übersetzungsgerechtes Schreiben für maschinelle Übersetzung
Texte werden üblicherweise geschrieben, um von Menschen gelesen zu werden. Durch den zunehmenden Einsatz von KI für die Texterstellung und Übersetzung kommt allerdings auch der Maschinenlesbarkeit eine große Relevanz zu. Soll ein Text maschinell übersetzt werden, gibt es einige Aspekte, die schon bei der Texterstellung berücksichtigt werden können, um sich dann positiv auf den Output von Machine Translation (MT) auszuwirken. Wir zeigen mögliche Stolperstellen beim Einsatz von MT-Systemen und Lösungsansätze, um durch MT-gerechtes Schreiben die Fehlerquellen und den Nachbearbeitungsaufwand im Posteditieren beim Einsatz maschineller Übersetzung deutlich zu reduzieren.
Die Maschine mitdenken
Beim übersetzungsgerechten Schreiben wird bereits bei der Erstellung eines ausgangssprachlichen Inhalts die spätere Übersetzung berücksichtigt. In unserem Beitrag zum übersetzungsgerechten Schreiben für das Arbeiten mit CAT-Tools sind wir zusätzlich auf den Einfluss von Layout und Terminologie auf die Übersetzbarkeit und vor allem die sinnvolle Wiederverwendung von Übersetzungen in Translation Memorys eingegangen. Viele der dort aufgezeigten Aspekte beeinträchtigen zwar die Verarbeitbarkeit (und teils Verständlichkeit) des Textes, können aber bei der Humanübersetzung erkannt und korrigiert werden.
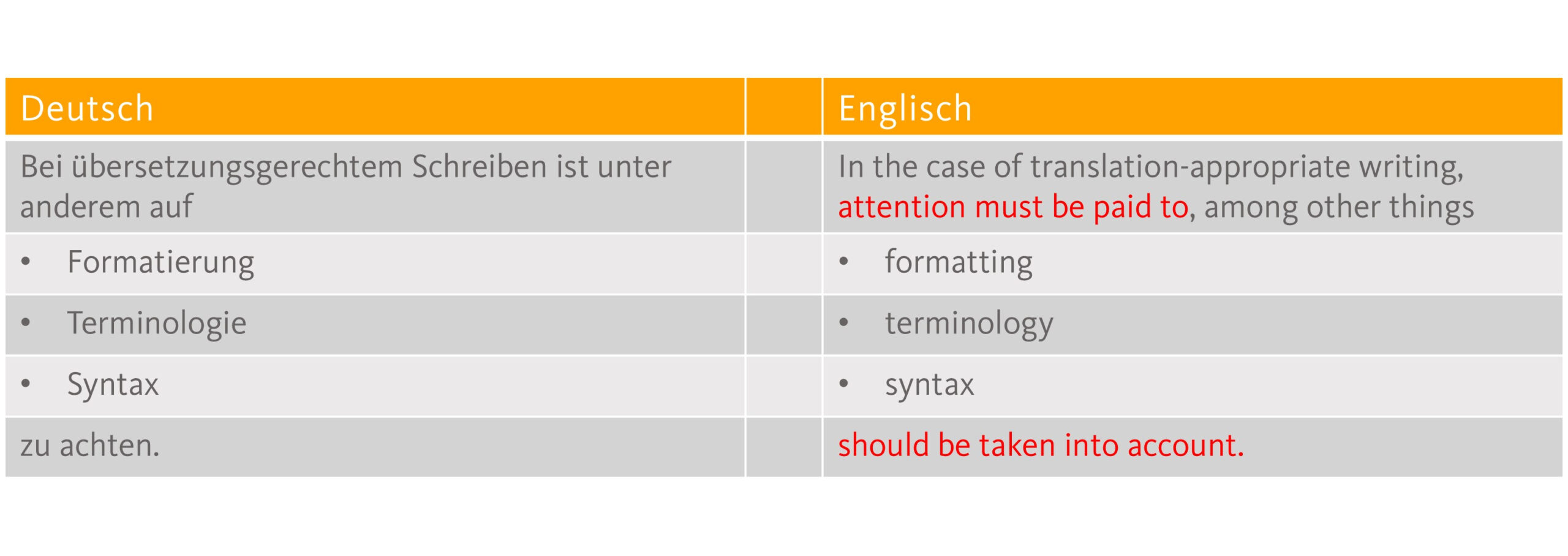
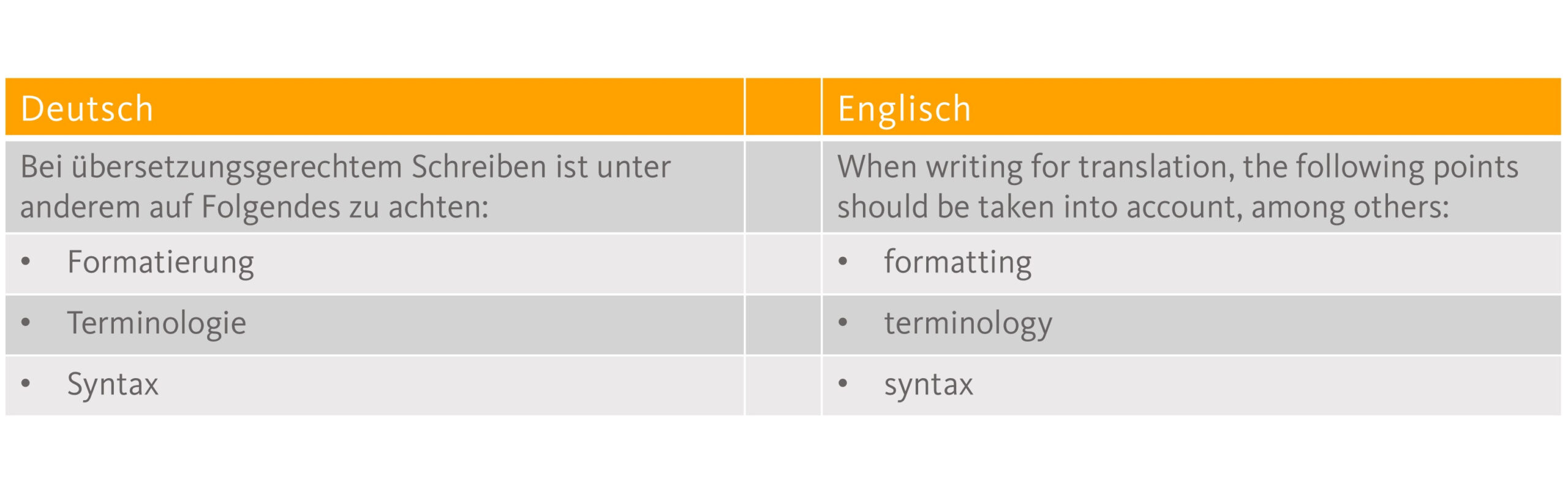
Anders sieht dies aus, wenn ein Text nicht von einem Menschen, sondern von einer Maschine übersetzt werden soll. Die Norm DIN 8579 „Übersetzungsgerechtes Schreiben – Texterstellung und Textbewertung“ listet Anforderungskriterien an übersetzungsgerechte Texte und bewertet deren Relevanz explizit auch für den Einsatz maschineller Übersetzung. Von den 47 Kriterien werden 40 als relevant für MT und weitere 3 als bedingt relevant bewertet. Fast alle Anforderungen für übersetzungsgerechtes Schreiben in Bezug auf Formatierung, Terminologie, Stil und Syntax sowie Eindeutigkeit und Logik treffen also für reine MT-Übersetzungen ebenso wie für Humanübersetzungen zu.
Übersetzungsgerechtes Schreiben zielt auf die Reduzierung von Zusatzkosten und Zeitverlusten sowie die Reduzierung von Übersetzungsfehlern ab. Diese Ziele gelten auch für maschinelle Übersetzung, die meist eingesetzt wird, um Zeit und/oder Kosten zu sparen. Für Humanübersetzungen kommt das Ziel hinzu, unnötige Rückfragen zu reduzieren. Genau hier wird ein Unterschied der beiden Prozesse deutlich, da maschinelle Übersetzungssysteme eben keine Rückfragen stellen. Jeder Fehler des MT-Systems führt entsprechend zu erhöhten Aufwänden bei der Nachbearbeitung oder kann ein Risiko darstellen, wenn er unentdeckt bleibt. Risikopotenzial schlummert dabei an unterschiedlichen Stellen in Texten und im MT-Prozess.
Segmentierung und Kontext
Maschinelle Übersetzung kann sowohl als Stand-Alone-Lösung als auch eingebunden in Drittanwendungen genutzt werden. In der alleinstehenden Variante können Texte oder Dateien im Webinterface eines Anbieters übersetzt werden. Für den Einsatz in Texterstellungs- oder Übersetzungssystemen kommen meist Plug-ins zum Einsatz, über die Übersetzungen z. B. in MS-Office-Programmen ausgelöst werden können. Im professionellen Übersetzungsbereich erfolgt die Nutzung über die Einbindung ins CAT-Tool, sodass die MT- Übersetzungen als zusätzliche Ressource neben dem Translation Memory genutzt werden können.
Um Fehlerpotenzial zu erkennen, ist es hilfreich, grundlegende Funktionsweisen von MT-Systemen zu kennen. Bei der Nutzung in CAT-Tools wird die Segmentierung des Textes ganz deutlich, da jeder Text segment- bzw. satzweise erfasst und übersetzt wird. Doch auch wenn ein ganzes Dokument an ein MT-System übermittelt wird, erfolgt im Hintergrund eine Segmentierung. Für die Erkennung von Zusammenhängen bedeutet dies: MT-Systeme erkennen Kontext nur bis zum Satzschlusszeichen bzw. dem Segmentende. Damit erfolgt keine Erkennung von Bezügen, beispielsweise Pronomen, über Satzgrenzen hinweg, wie folgendes Beispiel zeigt:

Laut Übersetzung ist nicht die Bushaltestelle rostig, sondern das Mädchen. Bezüge müssen daher entweder durch Wiederholungen aufgelöst werden oder zusammenhängende Sätze so miteinander verbunden werden, dass die Satzgrenze entfällt:

Large Language Models haben an dieser Stelle einen Vorteil, da Texte im Gesamtkontext betrachtet werden und keine segmentweise Segmentierung erfolgt.
Umbrüche und Satzbau
Eine klare Fehlerquelle für MT-Übersetzungen sind manuell eingefügte Umbrüche innerhalb eines Satzes, beispielsweise um eine Zeile an einer bestimmten Stelle zu trennen. MT-Systeme arbeiten auf der Basis von Wortwahrscheinlichkeiten. Für jedes Wort im Satz berechnet das System also per Wahrscheinlichkeit, welche anderen Wörter häufig mit diesem Wort zusammenstehen bzw. im Trainingsmaterial der Maschine gemeinsam vorkamen. Was eigentlich zu flüssigen und kohärenten Übersetzungen führt, kann im Fall von manuell umgebrochenen Teilsätzen allerdings unerwünschte Ergebnisse hervorbringen. Denn das MT-System ergänzt jeden Satzteil um anscheinend fehlende Informationen, sodass die ursprüngliche Aussage verloren gehen kann oder zusätzliche Informationen im Zieltext auftauchen können. Häufig stehen dann unabhängige Teilsätze nebeneinander, die keinerlei logische Verbindung mehr haben.
Harte, manuell eingefügte Umbrüche gilt es grundsätzlich zu vermeiden. Eine Alternative können weiche Umbrüche (↵) darstellen, die den gleichen Zweck erfüllen, aber nicht als Stoppzeichen gelten. Bei Übersetzungen können Umbrüche aufgrund unterschiedlicher Lauflänge allerdings an völlig anderer Stelle stehen und so die ursprüngliche Intention des Textumbruchs an einer bestimmten Stelle nicht mehr erfüllen.
Im Hinblick auf den Satzbau führen bei der maschinellen Übersetzung auch Sätze zu Problemen, in denen das Verb sehr weit vom Subjekt entfernt steht oder Sätze ohne Verb sowie Auflistungen, die im Deutschen erst am Ende geschlossen werden. Bei Satzklammern ergänzt das MT-System den ersten, unvollständigen Teil um die anscheinend fehlende Information. Diese Ergänzungen können im Fall von vergessenen Wörtern, also wirklicher Unvollständigkeit, sehr hilfreich sein, führen aber im Fall von Satzklammern häufig zu Doppelungen und damit fehlerhaften Übersetzungen:
Ein Lösungsansatz ist, Sätze so vollständig und zusammenstehend wie möglich zu formulieren. Für das oben gezeigte Beispiel kann die Einleitung zur Aufzählung beispielsweise vor dem ersten Aufzählungspunkt beendet werden, sodass keine Satzklammer entsteht:
Formatierung
Je nach MT-System können unterschiedliche Formatierungen innerhalb eines Satzes – wie Fett- oder Kursivschreibung oder unterschiedliche Schriftfarben – zu Schwierigkeiten bei der Übersetzung führen. Einige MT-Systeme betrachten jede Formatierung als eigenständigen Satzteil, was bei einer hohen Dichte an Formatierungen schnell zu Wort-für-Wort-Übersetzungen führen kann:

Um dieses Phänomen einzudämmen, ist es sinnvoll, den Umgang mit unterschiedlichsten Formatierungen für das eingesetzte MT-System zu testen. Besonders anfällig für formatierungsbedingte Fehlübersetzungen sind PowerPoint-Dateien, die deshalb gesondert geprüft werden sollten. Treten im MT-System Fehlübersetzungen auf, sollten die Formatierungen auf das Nötigste beschränkt werden und eher eine Nachformatierung nach der Übersetzung erfolgen.

Bei der Übersetzung in CAT-Systemen werden Formatierungen des Ausgangstextes als Tags, also Markierungen, im Übersetzungseditor dargestellt. Beim Einsatz von MT-Systemen kommt es häufig zu einer Verschiebung, Auslassung oder Ergänzung der Tags, sodass Formatierungen nicht korrekt in den Zieltext übertragen würden. Auch eine Auflistung aller im Satz enthaltenen Tags direkt am Satzanfang ist je nach eingesetztem MT-System möglich. Auch wenn dies die Übersetzung des Texts nicht oder kaum beeinflusst, führen Formatierungen also auch in CAT-Tools zu Fehlerpotenzial und damit einem erhöhten Aufwand bei der Nachbearbeitung.
Terminologie
Fachtermini sind sowohl bei der Human- als auch bei der maschinellen Übersetzung eine wichtige Stellschraube für Korrektheit, Angemessenheit und Verständlichkeit. Je nach eingesetztem MT-System, Sprachkombination und Sachgebiet der Texte kann die maschinelle Übersetzung allerdings sehr weit von der im Unternehmen verwendeten oder gewünschten Terminologie entfernt liegen. Zum einen kennen MT-Systeme die gewünschte Terminologie nativ nicht, zum anderen entscheiden Wortwahrscheinlichkeiten über die Übersetzung jedes Terminus. Dadurch können auch Termini, die im Ausgangstext einheitlich und korrekt verwendet wurden, im MT-Ergebnis trotzdem von Satz zu Satz unterschiedlich übersetzt werden. Wie erwähnt, betrachten die Maschinen keinen Gesamtkontext, sondern einzelne Sätze – und stellen dadurch keine Verbindung oder Einheitlichkeit zwischen den Termini im gesamten Dokument her. In maschinellem Output ist also neben terminologischen Fehlern oder Ungenauigkeiten vor allem mit Inkonsistenzen zu rechnen.
Ein besonderes Augenmerk sollte erlaubten Synonymen – zum Beispiel Kurzformen – gelten, die im Ausgangstext verwendet werden, um Termini nicht zu wiederholen. Wird zum Beispiel ein Terminus wie „Innensechskant-Schraubendreher“ im darauffolgenden Satz zu „Schraubendreher“ abgekürzt, können menschliche Übersetzer:innen und Leser:innen wahrscheinlich einen Bezug herstellen. Für MT-Systeme beginnt durch den Satzendepunkt hingegen ein neuer Satz ohne Bezug zum bisherigen Text. Das System verwendet dann für „Schraubendreher“ die statistisch wahrscheinlichste Übersetzung:

Für den Einsatz von MT-Systemen gilt es daher, Kurzformen zu vermeiden und Fachtermini möglichst immer in der Vollform zu verwenden. Selbst wenn die Maschine Termini inkonsistent übersetzt, kann dank terminologischer Konsistenz im Ausgangstext gezielt nach Termini gesucht werden, um sie im maschinellen Output zu korrigieren.
Eine weitere Stolperstelle bei der maschinellen Übersetzung sind Abkürzungen. Mit Ausnahme sehr gängiger Abkürzungen wie EU, UNO oder DSGVO übernehmen MT-Systeme Abkürzungen meist wie im Ausgangstext:

Abkürzungen sollten daher wenn möglich ausgeschrieben und somit vermieden werden. Für alle genannten Punkte – Fachtermini, Kurzformen und Abkürzungen – kann als Lösungsansatz in einigen MT-Systemen ein Glossar eingebunden werden. In diesem werden pro Sprachrichtung terminologische Vorgaben erfasst, die das System dann direkt in die maschinelle Übersetzung übernimmt. Dabei können nicht nur Fachtermini berücksichtigt werden, sondern auch Phrasen, allgemeinsprachliche Wörter oder eben Abkürzungen und Kurzformen, wenn sie sonst zu Fehlern im maschinellen Output führen.
Glossarvorgaben ermöglichen auch Differenzierungen ähnlicher Wörter, die sonst vom MT-System identisch übersetzt würden. Denn die Systeme tendieren aufgrund der Berechnung von Wortwahrscheinlichkeiten und dem Training mit sehr großen Datenmengen zur Verwendung von eher simplen, gängigen Wörtern. Dies kann dazu führen, dass unterschiedliche, aber semantisch ähnliche Wörter gleich übersetzt werden:

Abhilfe kann hier das Hinterlegen von beispielsweise „Lack = varnish“ im Glossar schaffen, wodurch eine klare Differenzierung gegeben ist.
In einigen Sonderfällen übergehen die MT-Systeme allerdings Glossarvorgaben. Dies kann einerseits aufgrund von Kontextsensitivität geschehen, wodurch die Maschine für jede Vorgabe trotzdem die statistische Wahrscheinlichkeit berechnet und die Vorgabe nicht umsetzt, wenn sie laut Trainingsmaterial unwahrscheinlich ist. Doch auch Satzzeichen innerhalb einer Glossarvorgabe, zum Beispiel der Bindestrich bei aufgesplitteten Komposita wie „Luft- und Kriechstrecken“, werden von einigen MT-Systemen ignoriert. Es erfolgt dann kein Bezug zwischen dem abgetrennten Wortteil und dem Grundwort, sodass der abgetrennte Teil alleinstehend übersetzt wird. Aufgesplittete Komposita sollten daher vor der maschinellen Übersetzung ausgeschrieben werden, also z. B. „Luftstrecken und Kriechstrecken“, um klare Bezüge für die MT herzustellen.
Mehrsprachigkeit, Referenzen und Metaebene
Auch wenn MT-Systeme scheinbar mühelos zwischen verschiedensten Sprachen hin- und herwechseln können und viele Online-Dienste eine Option zur automatischen Spracherkennung anbieten, stellt Mehrsprachigkeit in Ausgangstexten eine potenzielle Fehlerquelle bei der maschinellen Übersetzung dar. Enthält ein deutscher Text beispielsweise englische Textteile in Aufzählungen oder zweisprachige Tabellen, kommt es bei einer Übersetzung ins Englische immer wieder vor, dass die bereits englischen Texte „übersetzt“ werden und sich deren Wortlaut ändert.

Auch kulturspezifische Bezüge wie Maßeinheiten, Institutionen, Redewendungen oder Satzbeispiele für bestimmte Phänomene können von den MT-Systemen nicht umgesetzt werden, ebenso wenig wie Anpassungen auf der Metaebene, also zum Beispiel zu Aussagen über Satzlänge oder Anzahl enthaltener Wörter:

Genauso, wie das MT-System im hier gezeigten Beispiel nicht die Wörter des englischen Satzes zählen kann, kann es auch nicht nach Referenzen zu anderen Dokumenten, Gesetzestexten oder Normen recherchieren. Explizite Verweise auf solche Sekundärtexte können vom MT-System nur übersetzt werden und entsprechen damit eventuell nicht dem tatsächlichen fremdsprachigen Titel einer Referenz. Neben der oben erwähnten Mehrsprachigkeit wird bei der maschinellen Übersetzung auch nicht berücksichtigt, wenn bestimmte Satzteile oder Wörter in der Ausgangssprache beibehalten und nicht übersetzt werden sollen.
Jegliche Kulturspezifika und Verweise auf Referenzdokumente müssen daher vor der maschinellen Übersetzung bereits übertragen oder im Anschluss korrigiert werden. Jedes Dokument sollte außerdem auf das Vorkommen mehrerer Ausgangssprachen überprüft werden. Bereits vorhandene fremdsprachige Inhalte müssen dann gar nicht erst an das MT-System übermittelt werden, um keine „Übersetzung“ und damit eventuell unerwünschte Anpassung zu riskieren.
Fazit: Vorarbeit statt Nacharbeit
Auch wenn maschinelle Übersetzung längst auch im Unternehmensalltag angekommen ist, gilt es bei der Texterstellung einige Punkte zu beachten, über die Maschinen „stolpern“ können. Beim übersetzungsgerechten Schreiben für maschinelle Übersetzung spielen unter anderem die Aspekte Segmentierung, Satzbau, Formatierung und Terminologie eine Rolle. Grundsätzlich sollte so explizit und vollständig wie möglich formuliert werden, da satzübergreifende Bezüge, synonym verwendete Fachtermini und Kurzformen zu Fehlern führen können.
Gerade bei vielen Zielsprachen und bei großen Textvolumen zahlt es sich aus, etwas Aufwand in die Vorbereitung der Texte, das sogenannte Präeditieren, zu stecken, um potenzielle Fehlerquellen beim Einsatz von MT zu beheben.
Wenn dann die Ausgangstexte für Maschinen gut lesbar sind, dann werden es die Zieltexte für die Leser:innen hoffentlich auch sein.
Möchten Sie mehr über das übersetzungsgerechte Schreiben für die maschinelle Übersetzung erfahren? Dann nehmen Sie noch heute Kontakt mit uns auf für eine individuelle Beratung.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.