Customising machine translation systems
17/01/2023
MT training: Does practice still make perfect?
Generic translation systems now offer a number of features for customising translation results, with the result that users in companies are asking themselves whether a specially trained MT engine is worthwhile at all any more. Our head of MTPE and terminology management, Jasmin Nesbigall, discusses this question using results of comparative analyses from a specific customer project.
There is now a number of ways to adapt the translation results of generic MT systems to individual company requirements, from specifying forms of address and distinguishing between female and male job titles to adapting machine results for similar translation hits from translation memory systems and defining subject-specific terminology. These functions promise a better output, meaning less time is spent post-processing the text while the costs are kept manageable.
While system providers are almost in a race to offer the best features, many users are rightly asking themselves whether customisation, i.e. an MT engine trained specifically for the company, is still worthwhile at all.
After all, training an MT system remains a black box, as the quality of the translation can only be reliably assessed after customisation has been completed. In addition, data compilation, cleaning and specific training take a lot of time and cost a lot of money.
To shed some light on this black box, it is worth taking a look at companies that have gone the MT training route. We provided one of our clients with comparative analyses before and after the training and in this article we share the insights gained.
Influencing factors in machine translation
At the moment, generic machine translation systems in particular are outdoing themselves not only with additional language combinations, but also with the new features already mentioned, so that they can eliminate previous sources of error.
While the choice between addressing the reader formally and informally and using gender-appropriate job titles make sense for many professional translations but may only have a low degree of effectiveness, the machine adaptation of fuzzy matches promises a significant leap in quality and productivity. The machine searches for similar segments from the translation memory system and then merely adapts it where it is different. This reduces the manual work required during post-editing and leads to significantly more consistent translations.
So far, the really big sources of error when using generic MT systems have come from the use of specified terminology that cannot be implemented by freely available engines, or at least not reliably. Although the systems translate with linguistic fluency and coherency, they do not know any company-specific requirements and may therefore deliver technical terms in the translation that do not correspond to user specifications or preferences.
Until now, there has been no way around using a company-specific MT engine to implement the desired terminology, although even this cannot guarantee success, because the output of trained engines depends on the quality of the training data. And for technical terms this means that if they are consistent and included in sufficient number in the training material, they will be reliably implemented in the translation. However, if the training data contains unclean terminology with many synonyms, different spellings and inconsistent equivalents, even the trained MT system will not be able to deliver uniform specialised terminology when deployed. The well-known motto applies: garbage in, garbage out.
In some MT systems, for example TextShuttle and DeepL, terminology can be integrated into machine translation in the form of a glossary. This means that desired technical terms are transmitted to the system and compliance with them is enforced. Given the previous potential for errors and the large amount of time required to edit and correct terminology, this function is naturally met with enthusiasm. This is because a glossary can be created much more quickly and cost-effectively than training an MT system with company specifications. At the same time, the option is more dynamic, as a glossary can be continuously expanded or adapted. However, forcing does not always lead to the desired results or, depending on the specifications, is sometimes done “using a sledgehammer” without taking the context into account.
There is definitely a lot happening with additional features for machine translation. But are these enough to make company-specific training superfluous? We look into the details and analyse whether and to what extent translation quality can be increased through MT training. Fortunately, we can do this for six languages at once.
The background story: Use of generic engines and special features
One of our clients in the software sector has been using MTPE for translation projects for many years. In the first year, the machine pre-translation for all six required target languages was done with the same generic engine. Then the MTPE team at oneword analysed the output of three different MT systems for their suitability for the company’s texts. The result: for four languages, a different MT system delivered better results in tag positioning, reader address and translating calls to action. From this point on, two different MT systems were used, depending on the target language, which led to very good ratings from the post-editors and an improved word throughput during post-editing.
The facts: Categorising the effort post-editing takes
At oneword, we carry out extensive analyses after the project has been completed to evaluate the PE effort and the quality of the MT pre-translation. We divide the machine-translated segments (MT segments) into three categories:
- How many MT segments did not have to be edited at all?
- How many MT segments only had to be lightly edited (max. 15%)?
- How many MT segments had to be extensively edited or completely re-translated?
If one third of the output falls into each of the categories, we are in a range expected for MTPE. However, the more segments that fall into categories 1 and 2, the less post-editing is needed and the more suitable the project is for MTPE.
For our client, after using the two generic MT systems, 15% to 34% were in category 1 and 21% to 35% in category 2, depending on the target language. Coupled with good ratings from our post-editors, the MTPE projects had a satisfactory result. However, for various reasons “Never change a running system” was out of the question for our client.
The plan: Providing all languages simultaneously
In addition to a pronounced and innate affinity for technology, what distinguishes the company’s documentation department is the way in which it constantly questions processes and continuously looks for optimisations. Even when the company used MTPE for the first time, the aim was to be able to provide all of the software’s languages at the same time. For this purpose, pure machine pre-translation is used in the first step and post-editing is done in parallel. After post-editing, the final texts are imported into the software and the client can see them again. This approach has two key requirements:
- Pure machine pre-translation is of a high enough quality to be shown to clients.
- Little time spent post-editing so that the final texts can be delivered as quickly as possible.
In addition to implementing these requirements, it is important to take a look at the previous sources of error. What takes the most effort during post-editing and which errors are so serious that they hinder or prevent the use of pure machine translation output? In addition to specifics, such as the implementation of tags and the wording of calls to action, terminology and style guidelines in particular were identified as requiring a high level of post-editing. At the same time, the company can rely on high-quality translation memory data because of very intensive internal quality checks of translations and professional terminology work. It was the perfect starting point for training the MT engines, which was the next logical step for our client.
Training or customisation?
In the context of MT, “training” actually describes setting up a completely new MT system for a language pair. Real training therefore usually takes place with the provider itself, for example if a new language is being offered. The colloquial term “training for a company”, which we also use, is actually customisation in technical terms: a provider’s existing system (generic or domain-specific) is used and further trained with company data.
Boost in quality: MT training for all language pairs
After selecting the provider, the system was trained by our client in a total of seven languages, including a completely new language direction, for which the complete translation of the software was running in parallel. After tests and evaluations with the provider and in house, it was exciting to analyse the performance of the specific systems in actual use. For this purpose, each project that was pre-translated with the company-specific engine was analysed to determine the amount of post-editing work and the number of changed segments it required. The results delighted both us and our client:
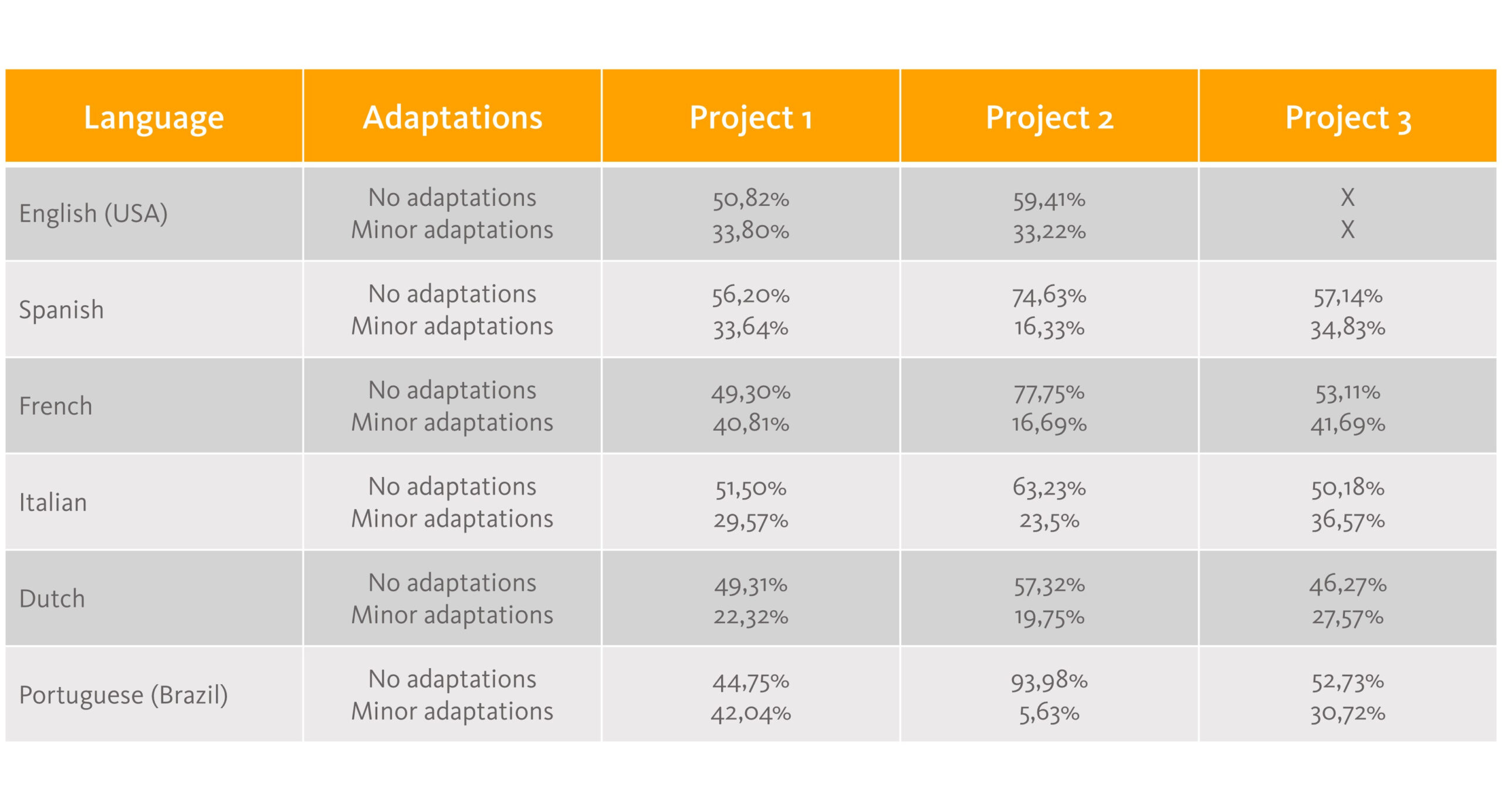
Overview of the customisation: Proportion of segments in category 1 (No adaptations) and category 2 (Minor adaptations) in each target language for three analysed projects (source: oneword GmbH)
There was a particularly noticeable increase in the proportion of segments in category 1, which can be adopted from the MT without changes. The average value across all languages was 58%, so more than half of all segments have to be checked by post-editors, but not edited. This contributes towards the requirement, mentioned above, to make the machine translation temporarily available with as few edits as possible. In addition, depending on the language, 5% to 42% of segments only require minor adjustments. The bottom line is that, depending on the target language and the project, up to 90% of the segments required little or no editing. From an MTPE perspective, absolute dream results!
Yet it is not only the pure numbers that are in favour of MT training, but also the options for fixing errors. In a detailed error analysis, we were able to show which sources of error still exist after the training and how these can be categorised. Among other things, it became apparent that the use of tags around GUI texts (for example, to highlight an interface text) repeatedly leads to errors because too much or too little text, or the wrong text entirely, ends up within the tags. Words whose singular and plural forms are identical (for example, Parameter in German) also cause errors in the translation, as expected. The clear advantage with MT training is that through close contact with the provider, identified error sources can be discussed and then potentially remedied. Whereas with generic systems you have to take what you can get, MT training offers ways to further improve the output even after the initial provision of the system.
Conclusion: Practice continues to make perfect
Even though training one or more of your own engines is still like a black box, our direct comparison showed that it can be a worthwhile step. The company’s requirements for using the pure MT output and minimising the amount of post-editing required are fulfilled with very good MT results, meaning that even pure machine output can be used temporarily. The features mentioned at the beginning – such as the adaptation of fuzzy matches – become obsolete when the system is trained with data from the translation memory, as the system learns from the existing translations and implements them in new texts. As well as terminology integration via the training material, many providers of trainable MT systems also offer a glossary function to adapt the MT output more quickly to changing terminology.
It is also possible to analyse existing errors and, together with the MT provider, check how they can be avoided. Here, too, glossaries can be used in some cases to store individual words or even special phrases and force them to be implemented. Another big advantage that is often overlooked is the fact that, unlike generic engines, trained engines make the machine output reproducible. Google Translate, DeepL and other similar MT may translate a text differently one week to the next because of further data input, but after customisation the results are identical until the system is adapted to new circumstances through re-training. However, since even trained engines cannot work magic, it is always worthwhile to have a post-editing guide for them, just as it is for generic MT. This sensitises people to sources of errors and contains tactics for eliminating them as efficiently as possible.
Would you like to learn more about training company-specific engines, comparative analysis, evaluating errors or creating post-editing guides? Then get in touch with us at mtpe@oneword.de.
8 good reasons to choose oneword.
Learn more about what we do and what sets us apart from traditional translation agencies.
We explain 8 good reasons and more to choose oneword for a successful partnership.