24/09/2024
Post-editing machine translation: why even AI does not make translators redundant
Revolutions in the translation sector are often heralded by two letters, such as the launch of translation memories (TM) in the 1990s and the use of machine translation (MT) from the mid-2010s. The trend has been confirmed once again since 2022 with the hype surrounding AI. The language industry generally tends to condense many concepts into two letters to save time and space. From AA for Afar to ZU for Zulu, ISO 639-1 lists a total of 183 two-letter language abbreviations. Many services and processes also have common abbreviations, such as HT for human translation and QA for quality assurance. This is actually interesting behaviour for an industry that thrives on correct language and comprehensibility.
Post-editing – usually abbreviated to PE – also saves time: the hope or expectation is that machine pre-translation and human post-editing save significant time and costs compared to a human translation. However, as quality should not suffer as a result of faster, and therefore cheaper, processing, the notion ‘Good, fast, cheap – pick two of them!’ seems to have had its day. The hype around AI has given this set of expectations another breath of fresh air, so it’s high time that we take a look at the requirements for post-editing.
Post-editing: efficiency gain or illusion?
‘We have it pre-translated by the machine and then someone just quickly reads over it.’ This sentence hits translation service providers and translators hard – both because potential translation volumes are disappearing and because years of experience have shown that no MT system translates without errors and that the devil is often in the detail.
The success of MTPE, i.e. human post-editing of a machine pre-translation, is measured by the effort involved in the post-editing process: what percentage of the MT output had to be amended by the post-editors and to what extent? At oneword, we use the ‘rule of thirds’ when evaluating the MT output: it makes sense to use MTPE if at least one third of the output does not need to be corrected at all, one third only needs to be slightly changed and at most one third needs to be significantly changed or completely retranslated.
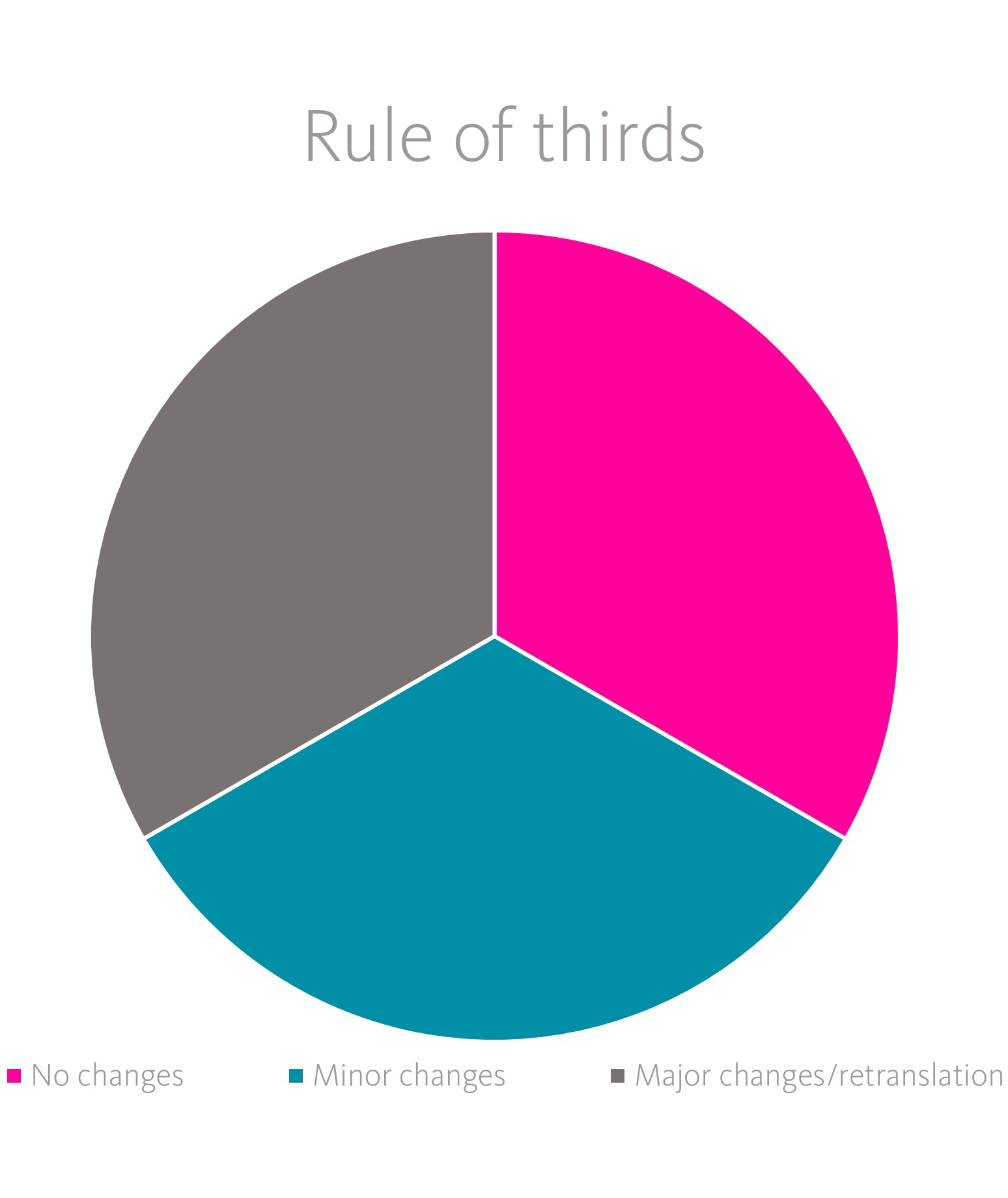
The higher the values in the first two categories, the more efficient the MTPE process is. Conversely, if a high proportion of the text falls into the final category, it is a clear indication that MTPE was not a good choice for a project.
Weak point in the analysis
As important as it is to conduct analyses and evaluations after post-editing, focusing on change metrics has two drawbacks. Firstly, evaluating the percentage of deviation from the original MT output does not automatically say anything about the cognitive effort involved in making a change or the severity of the corrected error.
The insertion or omission of the word ‘not’, for example, is only a minor adjustment requiring little effort, but can fundamentally change the content of a text. Completely restructuring a sentence to the specifications of a style guide or to bring it in line with a previous sentence may constitute a major adjustment. However, not making the adjustment would pose little to no potential risk.
Secondly, the degree of change itself does not indicate how much cognitive effort was required to make the change. A sentence may have to be read two or three times and the necessary information researched before it is approved unchanged, and this would fall into the ‘no changes’ category. Conversely, if the MT output is deemed incorrect and inappropriate at first glance, the post-editor can sometimes provide a completely new translation more quickly than they could revise the existing sentence.
Smart machines, smart mistakes
Neural machine translation and, more recently, large language models (LLM) that are used for translation often impress people with their fluent and coherent-sounding output. This makes it all the more difficult not to be blinded by their linguistic elegance when post-editing and to recognise the sometimes very subtle errors. In practice, it has been shown time and again that errors are even more likely to be overlooked if the pre-translation requires very few corrections overall. When a real slip-up creeps in between all the little mistakes, the results can raise eyebrows, as the following example shows.
This text was actually about an alternative ship propulsion system using wind sails. However, the result immediately puts you in a fantasy world, suggesting an idea that would make container transport much more impressive:

Post-editing: more than just a correction loop
Post-editing is often compared to proofreading or revision. After all, there is already a translation available and it ‘only’ needs to be checked. When revising a human translation, in the best-case scenario, only minor changes or no changes need to be made and it is assumed to be correct as a general principle. However, MT output is much less reliable: while ten sentences in a row may contain no errors and flow smoothly, sentence 11 may contain significant errors, completely miss the mark, contain a break in style or be completely unusable due to tags, sentence structure or word choice. The all-or-nothing rule applies particularly to sentences or parts of sentences without context (e.g. tables in manuals): MT output can either be completely correct or completely wrong.
People often argue that machine pre-translation can at least always be used as a starting point and that it is quicker to correct existing output than to translate a sentence from scratch. In response to this argument, it helps to list the steps involved in post-editing:
- Reading and checking the machine pre-translation
- Decide whether the pre-translation can be used as is, must be adapted or cannot be used.
- Confirm the translation, revise or delete the MT output or completely retranslate.
The steps that involve checking the MT output and deciding on how to proceed happen in addition to the ‘human translation’, which only starts once these steps are completed. If a new translation is required, the pre-translated sentence must be deleted and the new translation inserted. In addition to the extra work involved in deleting the MT output, the translator’s new sentence will in most cases be influenced by the previous translation that they have just read, making it difficult for them to translate freely and creatively in their own style.
The translator’s own style and usual way of working generally take a back seat when post-editing. According to DIN ISO 18587, which standardises the post-editing of machine translations, as much MT output as possible should be used and changes should only be made if they are necessary. To reduce the effort involved in correcting the translation per sentence from the outset, a structured approach is also common. This involves, for example, searching for incorrect technical terms and replacing all instances of them at the start of the project or processing certain check criteria immediately. An efficient post-editing process therefore requires not only specialist knowledge but also technical expertise in how MT works and the supporting functionalities in CAT tools.
When post-editing is complete the task is not quite finished, because it is crucial for MTPE projects that there is feedback on the MT system, and that error sources and the potential for optimisation are documented. This involves questions about what kind of errors occur in the MT output and whether and how these can be avoided, for example by integrating a glossary or adapting the source text. Therefore, another task for post-editors is analysing and categorising errors made by the MT systems. In response to repeated poor feedback, remedial measures can be taken, for example switching to a different MT system or excluding MTPE for a specific language or text type.
As post-editors are the professionals who interact the most with the MT output and correct it, they are often assigned additional tasks after project completion, such as creating or updating PE guidelines to document typical specifications and pitfalls.
The influence of AI on MTPE
As large language models emerge and begin to be used for translation, language experts are being given numerous new tasks, including comparing the output of different MT systems and LLMs, creating glossaries, and performing analyses, data optimisation and prompt engineering in order to provide the AI with certain specifications. Compared to a traditional MT system, an LLM can be quickly taught that a colon should be used for gender-neutral terms in German or that active formulations should be used, for example. AI can also help with post-processing the MT output to comply with certain specifications, such as the correct way to formulate instructions or use technical terms. Initial interfaces with CAT systems are already available, and many more are sure to follow.
However, the hype surrounding AI brought up a question that the translation sector has been asking since at least 2016, when neural machine translation first emerged: Will translators soon be redundant because machines are replacing humans?
The field of translation has evolved continuously in recent years and adapted to new circumstances, including the use of machine translation.
Ideally, however, the question is more about which tasks machines can support humans with. As we have shown, the translation process can be significantly accelerated by using MT and AI. However, the humans involved are always the ones who perform the crucial and cognitively demanding tasks that ensure short- and long-term quality levels, such as post-editing itself, error analysis and process support strategies. In the best-case scenario, MT support also frees up time for other important tasks, such as creative translation, linguistic nuancing or language engineering for process optimisation and data control. The much-cited ‘human-in-the-loop’ approach is therefore far from obsolete. However, it should be called a ‘human-in-control’ approach instead, in which MT and AI act as helpful co-pilots. Neither human nor machine is superfluous in this scenario; they support each other.
If you also use machine translation or are thinking about it and want to rely on quality and expertise, then get in touch with us right away.
8 good reasons to choose oneword.
Learn more about what we do and what sets us apart from traditional translation agencies.
We explain 8 good reasons and more to choose oneword for a successful partnership.