27/05/2024
Term extraction and AI: how to get it right.
Term extraction is the first step in extracting specialised terminology and creating a terminology database. How the extraction is carried out depends largely on the database and the time and personnel resources available. This is because working manually quickly becomes extremely time-consuming when the source files are extensive. And, at the moment, AI is always called upon if manual tasks need to be supported or automated. But what does term extraction look like? Is it enough to formulate a prompt to extract all the specialised terms from a text? We pitted human, machine and AI against each other in several tests with different texts and prompting strategies. Here we present the results and show the advantages and disadvantages of each of the three options.
The preparation: materials and manual reference results
What AI is to text creation, the sponge city concept is to urban planning: innovative and a buzzword on everyone’s lips. So it seems appropriate that for our tests, we selected two texts about sponge cities and climate-adapted urban development. Both texts contained a high density of terminology with specialised terms from the environmental, urban development and climate adaptation domains. Texts of significantly different lengths were chosen to take into account how text length may impact the results: text 1 comprised 1658 words, text 2 more than five times as many at 9803 words.
With increasing text lengths, manual extraction is not really an option day to day: it is too complex, too time-consuming and too expensive. While terms from a short text can be quickly entered manually (and doing so is sometimes even quicker than using software), for longer texts, this creates quality issues and takes a lot of time. When a text reaches a certain length, the concentration of those working on the text wanes and they become unsure whether they have already recorded a term or not. This often leads to terms being extracted several times, which can be easily detected and eliminated at the end of the process, but causes additional work during extraction.
The human result is considered the gold standard for extraction, particularly when you consider that results extracted by software always have to be checked manually or suggested candidates have to be validated. It was therefore important for our tests to obtain reference values by first performing manual extractions, which would then serve as a benchmark for the results of the tools used.
To keep this benchmark as objective as possible, each manual extraction was carried out by two people, and the results were compared with each other and then combined. 113 terms were extracted from text 1; from text 2 there were 299 terms. As there was a high density of terms in the texts overall, the figures matched what happens in practice: in short specialised texts terminology is often densely packed, whereas in longer texts it is often repeated.
The results served not only as a quantitative reference, but also as a qualitative one: during the subsequent tool-based extraction, the only terms that were validated were those also extracted in the manual process. This meant that the tool results were compared with the reference values.
Challenger 1: Extraction software
The first tool-assisted extraction was carried out in the ‘traditional’ way, with extraction software. Several runs were carried out for both texts with different settings for data noise and maximum term length.
In the short text 1, terms usually only appeared once, which led to inadequate results with the default settings. This was also reflected in the raw extraction result, which found between 67 and 612 terms depending on the setting. This was followed by manual validation to obtain the actual relevant technical terms from the proposed candidate terms. When run with the optimum settings, 98 terms were validated. This is 86.73% of the reference value of 113 terms from the manual extraction.
Text 2 was also processed in several runs with different settings. With raw results of between 538 and 2526 terms, the number of identified terms was significantly higher. In the best result, 259 of the 299 terms, i.e. 86.62% of the reference result, were validated. Depending on the settings, the suggested candidate terms still had to be cleaned up linguistically, for example to correct plural forms to singular.
Even though the aim of the validation was only to compare the results with the reference result, additional terms were quickly detected in the raw result that were classified as terminologically relevant. A further run was therefore carried out in which the extraction was performed independently of the manual reference values, resulting in 30 additional validated terms. Let us explain. The extraction software delivers the raw result in list form and, therefore, it is much more concentrated than in the full text. This also reveals terms that may have been overlooked in the document because they appear in captions or footnotes. However, the list form also risks including and validating terms that are only part of a company name or appear in the bibliography.
Challenger 2: Generative AI
As there is more and more of a call for the use of AI for extraction, Large Language Models (LLMs) have been introduced as a third option. The question and hope behind this was: is it possible to carry out extractions with a clear instruction in the form of a prompt and with little effort and to obtain a list of results within seconds or a few minutes?
When using generative AI, prompting, i.e. formulating work instructions for the LLM, is of particular importance. In our tests, we therefore tried out various strategies, such as task-specific prompting, domain-specific prompting, combinations of both and also reverse prompting. The latter involves showing or describing the desired result to the system and asking it to formulate a prompt, with the aim of this leading to the result. A total of ten different prompts were used, some of which differed greatly in terms of their general instructions and the level of detail of these instructions. The best prompts were used several times, for example on different occasions. Three different models of ChatGPT (GPT-3.5, GPT-4 Turbo, GPT-4o) were used as the Large Language Model, as this is currently the most widely used tool. The text was entered directly into the input window and also transferred to the system as a file.
The low number of extracted terms was clear in all runs, especially in relation to the reference result. For the shorter text 1, ChatGPT delivered between 20 and 53 terms as a raw result, between 12 and 35 of which could be validated. The coverage was therefore 30.97% of the reference value. For the longer text 2, the AI suggested between 25 and 157 terms as a raw result, depending on the prompt, of which 5 to 75 (at most) were validated. Therefore, ChatGPT achieved a maximum coverage of only 25.08% for text 2. This means that only a quarter of the terms that a person had classified as relevant in the same text were detected and extracted.
The ten different prompts produced large differences in the raw and final results, as the following overview of text 1 shows.
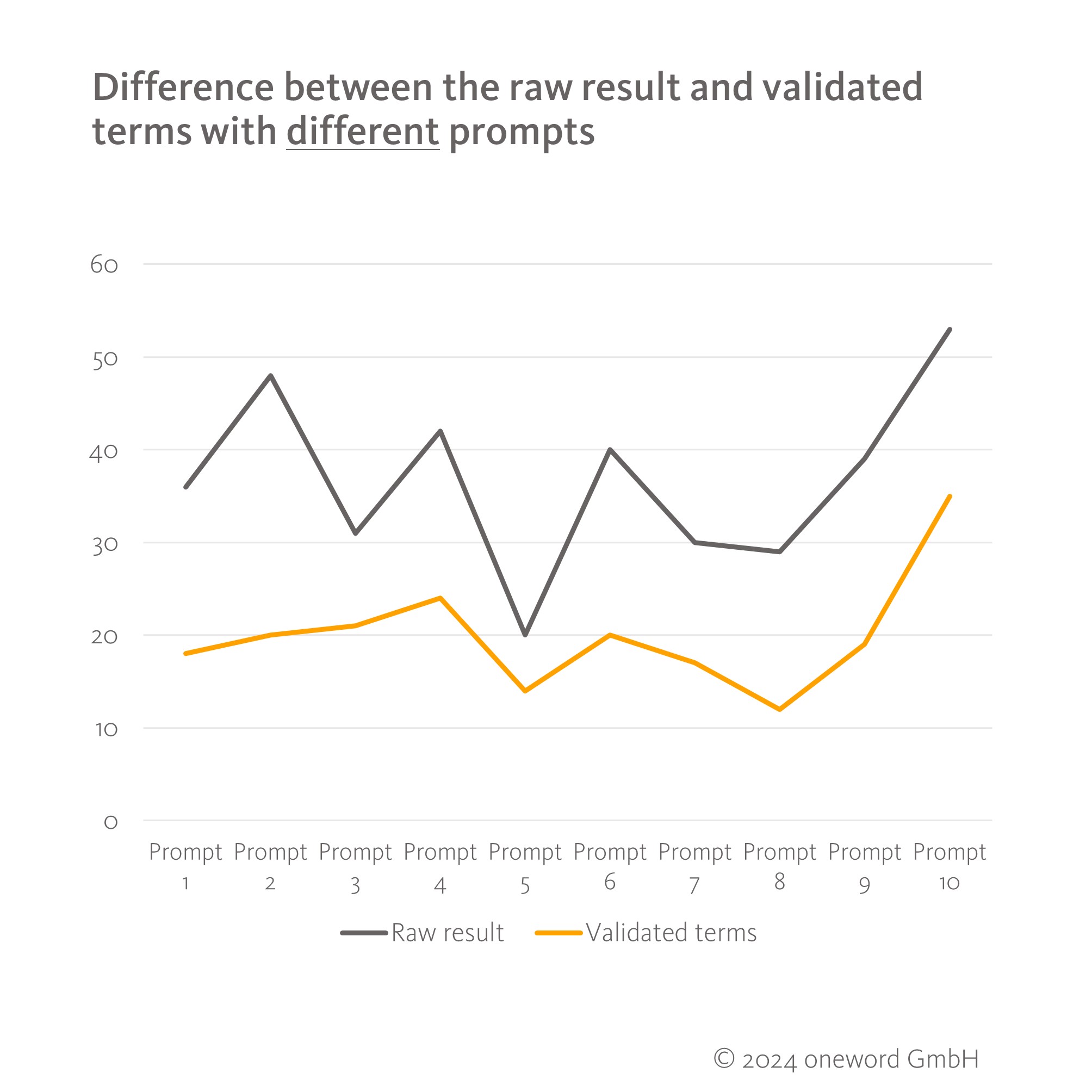
However, even identical prompts with identical input (same source text, same form of data input) never delivered the same result twice, but sometimes three times as many terms. Both the raw result and the number of validated terms fluctuated, even though the same prompt was used four times on different occasions. This is a good illustration of the lack of reproducibility that is often being discussed at the moment in relation to generative AI. It also puts the influence of the prompt formulation somewhat into perspective, as even the same input can produce very different results.
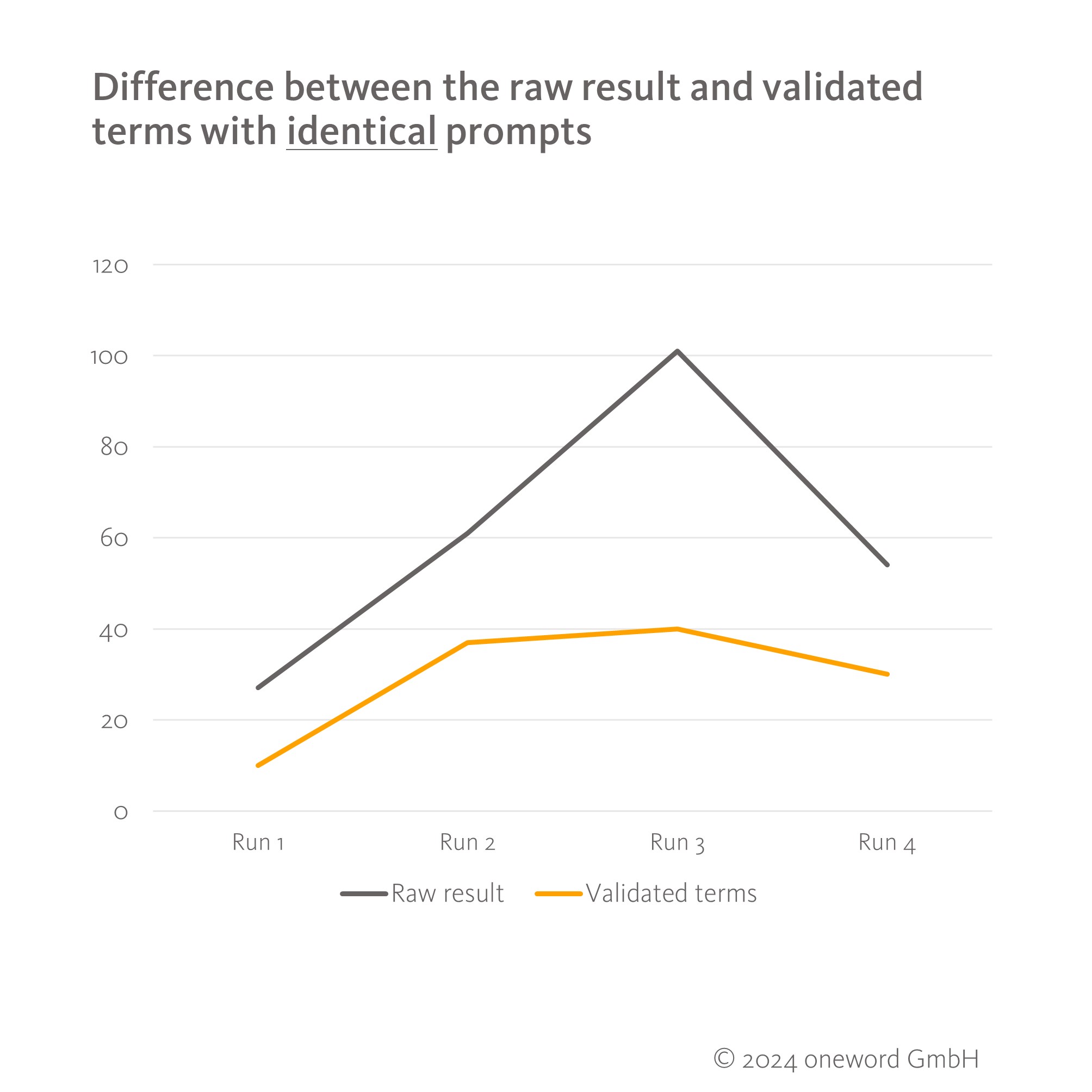
In addition to the lack of reproducibility, we encountered another weakness with AI in the tests that limits the reliability of the results: hallucinations. In a total of five runs, ChatGPT delivered terms that appeared technically correct but did not appear in the text at all. The newer ChatGPT-4o model hallucinated more frequently than the other two models.
Since the result of ChatGPT was significantly lower than that of the other methods, we began to assume that perhaps only high-frequency terms are extracted by AI. A further prompt instructed that, for each term, the LLM should also indicate how many times the term appeared. With the same text input, the system gave a frequency of 2 for the term ‘Bodenfunktion’ on the first attempt and a frequency of 8 on the next attempt. A manual check revealed that the term appeared a total of 29 times in the text. Even though it is not new knowledge that LLMs are not calculating machines, this shows that there is potential for errors when querying additional information about the extraction result. After further analyses, it could not be confirmed that the terms extracted by AI occurred more frequently in the texts than other, non-extracted terms.
The finishing line – and what to watch out for
Depending on the method used, term extraction can lead to very different results, as we have shown. However, a decision cannot be made on the final result alone, as, in day-to-day work, time and costs and any potential for errors and process risks must always be considered alongside the number of extracted terms.
In our tests, we documented how long the extraction took using each method. In all cases, however, it depends on how experienced you are with the tasks or the tool being used and, when using ChatGPT, whether you first need to formulate and test a prompt or whether a tried-and-tested prompt is already available.
For the longer text 2 (9803 words), the time comparison showed very clear results.
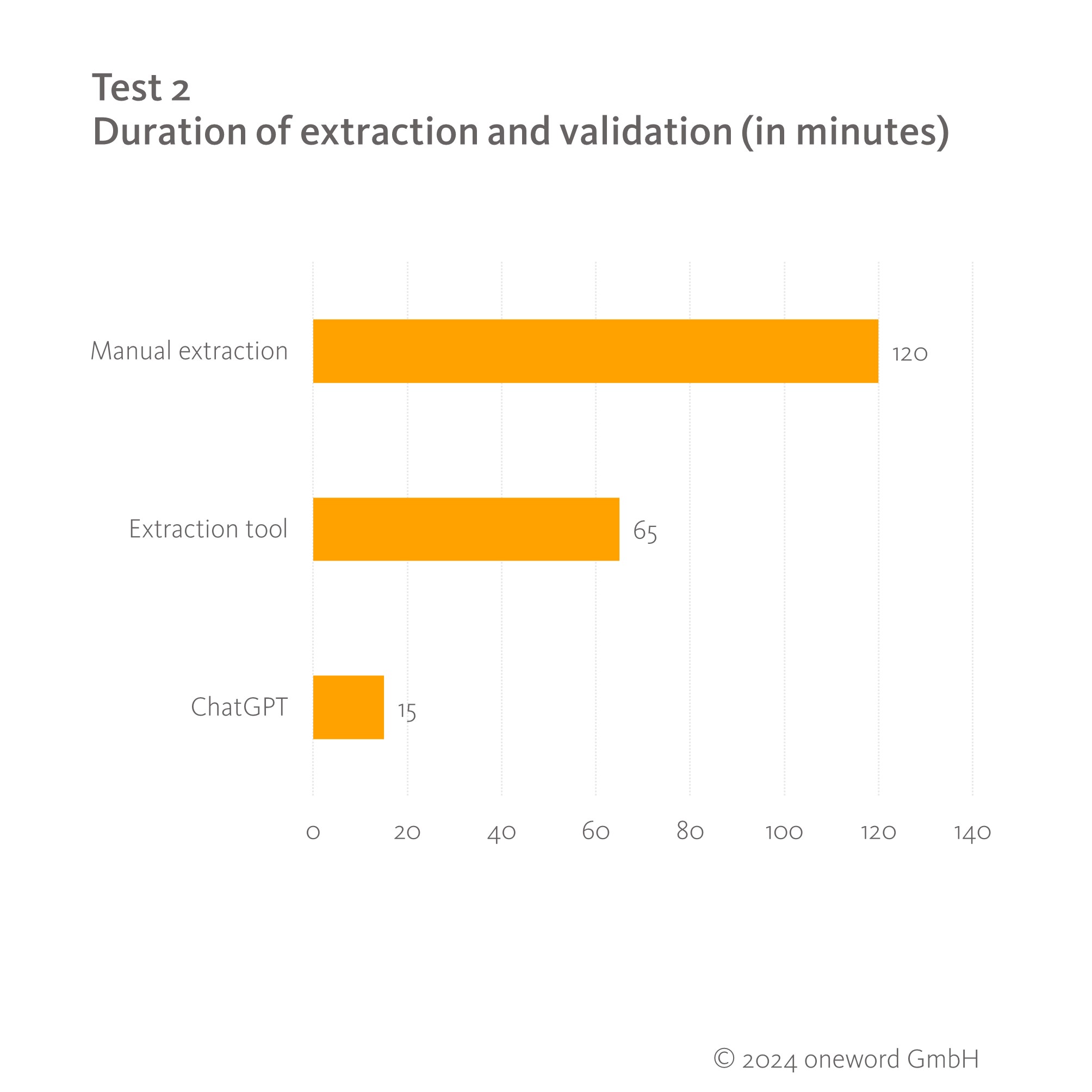
While using extraction software saves almost half the time of manual extraction, ChatGPT is the unbeaten fastest method, taking just one eighth of the time required to do the task manually. Formulating and entering a prompt is much faster than creating an extraction project in the tool or perusing several pages of a document. With ChatGPT, the results are also processed and output within a few seconds. The results obtained were all terminologically clean and could have been used without further editing, at least from a linguistic point of view. With both manual and software-assisted extraction, however, terms often had to be converted into their basic form.
Using ChatGPT for term extraction also has the advantage that the result can be requested in different formats (e.g. as a list, in columns, etc.) or file formats (e.g. Excel) for optimal further processing. This enables automation of the process to immediately fill a database based on the extraction results. And, in a work context, less time means lower costs.
Time, effort and costs are precisely the reasons why manual extraction, which was considered an important benchmark in our tests, is usually not a realistic option in day-to-day work. After all, term extraction is mainly used for large amounts of text. In these cases, human labour alone, which takes a lot more effort, is disproportionate to the larger quantity of terms that could be found.
Although the manual result was also used as a qualitative benchmark, human extraction also has potential for errors. As well as the additional terms which, as mentioned above, were also validated with tool extraction, and the susceptibility of errors due to the person’s dwindling concentration when there are large amounts of text, subjectivity plays a major role in the extraction. Two terminologists will probably never provide the exact same validation results, because there are always grey areas as to which words are really considered technical terms. In addition, different validation strategies influence the result: depending on how broadly you define a domain, you will validate more or fewer terms. In our example, the general domain is ‘environment and climate’ and the specific domain is ‘climate-adapted urban planning’. Including only the latter leads to significantly fewer validations than including the general subject area. In our test, we tried to relativise this subjectivity and influence by comparing the results of two terminologists and by using agreements and guidelines.
Conclusion: Many roads lead to term extraction
Although the three analysed methods of term extraction show clear differences, they can all be useful in different cases. Manual extraction as the gold standard may be the best-in-class in theory, but in day-to-day business it simply often fails due to its feasibility, and, as shown, it is not infallible.
AI delivers very fast, but sometimes incorrect, results, which – like everything that comes directly from a machine – must be checked with a critical eye. As it extracts significantly fewer terms, it is arguably unsuitable for use in a large extraction project or when a comprehensive terminology structure is required. However, the speed and automation of the process enables terminology to be built up ‘on the fly’, which means that a database can be built up gradually without much effort. The terms invented by AI that creep into the database and its lack of reproducibility, as seen in the different results obtained from the exact same input, must be viewed critically.
Software specialising in term extraction proved to be the optimal middle ground in the test. This solution is the standard in day-to-day terminology work and is certainly always a good choice. In our comparisons, the software achieved good results or even exceeded the reference value with less time spent. When using the tools, it’s important to choose the right settings for each project in order to increase the yield and reduce the amount of rework required.
Terms can therefore be extracted in different ways and with different results. Therefore, the key question is what you want to achieve and how many resources can be used to achieve it. In the end, however, term extraction is only possible with a human in the loop, as it is up to humans to check and validate the raw results from software or AI.
Would you like to find out more about term extraction or build up a terminology database based on your data? Our terminology team will be happy to help you: terminologie@oneword.de
8 good reasons to choose oneword.
Learn more about what we do and what sets us apart from traditional translation agencies.
We explain 8 good reasons and more to choose oneword for a successful partnership.