Customization maschineller Übersetzungssysteme
17.01.2023
MT-Training: Macht Übung noch den Meister?
Generische Übersetzungssysteme bieten mittlerweile einige Features für die individuelle Anpassung der Ergebnisse, sodass sich auch Anwender:innen in Unternehmen fragen, ob sich eine eigens trainierte MT-Engine überhaupt noch lohnt. Unsere Fachleitung MTPE und Terminologiemanagement, Jasmin Nesbigall, erörtert diese Frage anhand der Ergebnisse von Vergleichsanalysen aus einem konkreten Kundenprojekt.
Vorgaben zum Siezen oder Duzen, die Unterscheidung zwischen weiblichen und männlichen Tätigkeitsbezeichnungen, eine maschinelle Anpassung von ähnlichen Übersetzungstreffern aus dem Translation-Memory-System und fachspezifische Terminologievorgaben: Mittlerweile gibt es einige Stellschrauben, um Übersetzungsergebnisse generischer MT-Systeme an individuelle Unternehmensvorgaben anzupassen. Die Funktionen versprechen einen besseren Output und damit weniger Nachbearbeitungsaufwand bei gleichzeitig überschaubaren Kosten für die Nutzung.
Während sich die Systemanbieter beinahe einen Wettlauf um die besten Features liefern, fragen sich viele Nutzer:innen zu Recht, ob sich Customization, also eine eigens für das Unternehmen trainierte MT-Engine, überhaupt noch lohnt.
Denn das Training eines MT-Systems ist und bleibt eine Blackbox, da die Qualität der Übersetzung erst nach Abschluss der Customization verlässlich eingeschätzt werden kann. Demgegenüber stehen hohe Investitionskosten und der große Zeitaufwand für die Datenzusammenstellung, -bereinigung und das spezifische Training.
Um etwas Licht in diese Blackbox zu bringen, lohnt sich ein Blick auf Unternehmen, die den Weg des MT-Trainings gegangen sind. Wir haben einen unserer Kunden mit Vergleichsanalysen vor und nach dem Training begleitet und teilen in diesem Beitrag die gewonnenen Insights.
Die Stellschrauben der maschinellen Übersetzung
Gerade die generischen Allrounder der maschinellen Übersetzungssysteme überbieten sich aktuell nicht nur mit zusätzlichen Sprachkombinationen, sondern auch mit den schon genannten neuen Features, um bisherige Fehlerquellen zu beheben.
Während die Wahl zwischen formeller und informeller Leseransprache und die Verwendung gendergerechter Tätigkeitsformen für viele professionelle Übersetzungen zwar sinnvoll sind, aber eventuell nur einen geringen Wirkungsgrad haben, verspricht die maschinelle Anpassung von Fuzzy Matches einen deutlichen Qualitäts- und Produktivitätssprung. Die Maschine sucht dabei ähnliche Segmente aus dem Translation-Memory-System und ergänzt dann nur die Abweichungen. Das reduziert die manuelle Nachbearbeitung während des Posteditierens und führt zu deutlich konsistenteren Übersetzungen.
Wirklich große Fehlerquellen beim Einsatz generischer MT-Systeme stellen bisher Terminologievorgaben dar, die von den frei verfügbaren Engines nicht oder zumindest nicht verlässlich umgesetzt werden können. Denn die Systeme übersetzen zwar sprachlich flüssig und schlüssig, kennen aber keine unternehmensspezifischen Vorgaben und liefern damit eventuell Fachtermini in der Übersetzung, die nicht den Vorgaben und Wünschen der Nutzer:innen entsprechen.
Für die Umsetzung der gewünschten Terminologie führte bisher kein Weg an einer unternehmensspezifischen MT-Engine vorbei, wobei auch diese keinen Erfolg garantieren kann. Denn das Ergebnis trainierter Maschinen steht und fällt mit der Qualität der Trainingsdaten. Und für Fachtermini bedeutet dies: Sind diese konsistent und in ausreichender Zahl im Trainingsmaterial enthalten, ist eine Umsetzung in der Übersetzung verlässlich. Werden allerdings terminologisch unsaubere Trainingsdaten mit vielen Synonymen, unterschiedlichen Schreibweisen und inkonsistenten Äquivalenten verwendet, wird auch das trainierte MT-System im Produktiveinsatz keine einheitliche Fachterminologie liefern können. Es gilt das bekannte Motto: garbage in, garbage out.
In einigen MT-Systemen, zum Beispiel bei TextShuttle und DeepL, lässt sich Terminologie in Form eines Glossars in die maschinelle Übersetzung einbinden. Gewünschte Fachtermini werden somit an das System übermittelt und deren Einhaltung forciert. Angesichts des bisherigen Fehlerpotenzials und des entsprechend hohen Nachbearbeitungsaufwands für Fachterminologie sorgt diese Funktion natürlich für Begeisterung. Denn ein Glossar ist deutlich schneller und kostengünstiger erstellt, als sich ein MT-System mit Unternehmensvorgaben trainieren lässt. Gleichzeitig ist die Option dynamischer, da ein Glossar kontinuierlich erweitert oder angepasst werden kann. Allerdings führt die Forcierung nicht immer zu den gewünschten Ergebnissen oder erfolgt, je nach Vorgaben, teilweise “mit der Brechstange”, ohne dass der Kontext berücksichtigt wird.
Es tut sich auf jeden Fall viel im Bereich der zusätzlichen Features für maschinelle Übersetzung. Reichen diese aber aus, um ein unternehmensspezifisches Training überflüssig zu machen? Wir schauen in die Details und analysieren, ob und wie sehr sich die Übersetzungsqualität durch ein MT-Training steigern lässt. Glücklicherweise können wir das gleich für sechs Sprachen machen.
Die Ausgangslage: Einsatz generischer Engines und Besonderheiten
Einer unserer Kunden aus dem Softwarebereich setzt bereits seit vielen Jahren auf MTPE für Übersetzungsprojekte. Im ersten Jahr erfolgte die maschinelle Vorübersetzung für alle sechs benötigten Zielsprachen mit der gleichen generischen Engine. Dann analysierte das MTPE-Team bei oneword den Output drei verschiedener MT-Systeme auf die Eignung für die Unternehmenstexte. Das Ergebnis: Für vier Sprachen lieferte ein anderes MT-System bessere Ergebnisse bei der Positionierung von Tags, der Leseransprache und der Übersetzung von Aufforderungen. Ab diesem Zeitpunkt wurden abhängig von der Zielsprache also zwei verschiedene MT-Systeme eingesetzt, was zu sehr guten Bewertungen der Posteditor:innen und einem verbesserten Wortdurchsatz beim Posteditieren führte.
Die Fakten: Kategorisierung des Aufwands beim Posteditieren
Zur nachträglichen Bewertung des PE-Aufwands und der Qualität der MT-Vorübersetzung führen wir bei oneword umfangreiche Analysen nach Projektabschluss durch. Wir unterteilen die maschinell vorübersetzten Segmente (MT-Segmente) dabei in drei Kategorien:
- Wie viele MT-Segmente mussten gar nicht bearbeitet werden?
- Wie viele MT-Segmente mussten nur leicht (zu max. 15 %) bearbeitet werden?
- Wie viele MT-Segmente mussten umfangreich bearbeitet oder komplett neu übersetzt werden?
Wenn sich die Ergebnisse zu jeweils einem Drittel pro Kategorie einordnen lassen, liegen wir in einem für MTPE erwartbaren Bereich. Je mehr Segmente jedoch in die Kategorien 1 und 2 fallen, desto weniger Nachbearbeitung ist nötig und desto besser ist das Projekt für MTPE geeignet.
Bei unserem Kunden lagen die Werte nach Einsatz der beiden generischen MT-Systeme je nach Zielsprache zu 15 bis 34 Prozent in Kategorie 1 und zu 21 bis 35 Prozent in Kategorie 2. Gepaart mit den guten Bewertungen unserer Posteditor:innen liefen die MTPE-Projekte also mit einem zufriedenstellenden Ergebnis ab. Aber: „Never change a running system“ kam für unseren Kunden aus einigen Gründen nicht in Frage.
Der Plan: Zeitgleiche Bereitstellung aller Sprachen
Neben einer ausgeprägten und von Haus aus vorhandenen Technikaffinität zeichnet sich die Dokumentationsabteilung des Unternehmens vor allem dadurch aus, Prozesse immer wieder zu hinterfragen und kontinuierlich nach Optimierungen zu suchen. Schon der erste Einsatz von MTPE erfolgte mit dem Ziel, möglichst alle Sprachen der Software gleichzeitig bereitstellen zu können. Dafür soll im ersten Schritt die reine maschinelle Vorübersetzung verwendet werden, während das Posteditieren parallel erfolgt. Nach dem Posteditieren sollen die finalen Texte in die Software eingespielt und den Kund:innen nochmals bereitgestellt werden. Dieser Ansatz bringt zwei zentrale Anforderungen mit sich:
- Eine ausreichend gute Qualität der reinen maschinellen Vorübersetzung, sodass diese bereits Kund:innen bereitgestellt werden kann.
- Ein geringer Aufwand im Posteditieren, um die finalen Texte möglichst schnell nachliefern zu können.
Neben der Umsetzung dieser Anforderungen ist ein Blick auf die bisherigen Fehlerquellen wichtig: Was verursacht den Hauptaufwand beim Posteditieren und welche Fehler sind so gravierend, dass sie die Nutzung der reinen maschinellen Outputs be- oder verhindern? Neben Spezifika wie der Umsetzung von Tags und der Formulierung von Aufforderungen wurden vor allem Terminologie und Stilvorgaben als hoher Nachbearbeitungsaufwand identifiziert. Gleichzeitig kann das Unternehmen aufgrund der sehr intensiven internen Qualitätskontrolle der Übersetzungen und durch eine professionelle Terminologiearbeit auf hochqualitative Translation-Memory-Daten zurückgreifen. Eine perfekte Ausgangsbasis also für das Training von MT-Engines, das für unseren Kunden der nächste logische Schritt war.
Training oder Customization?
Im MT-Kontext beschreibt das „Training“ eigentlich das Aufsetzen eines komplett neuen MT-Systems für ein Sprachpaar. Ein wirkliches Training erfolgt also meist beim Anbieter selbst, beispielsweise, wenn eine neue Sprache angeboten werden soll. Das umgangssprachlich und auch bei uns so bezeichnete „Training für ein Unternehmen“ ist fachterminologisch eigentlich eine Customization: Dabei wird ein vorhandenes System eines Anbieters (generisch oder domänenspezifisch) genutzt und dieses mit Unternehmensdaten weitertrainiert.
Der Qualitätsbooster: MT-Training für alle Sprachpaare
Nach der Anbieterauswahl erfolgte bei unserem Kunden ein Systemtraining in insgesamt sieben Sprachen, darunter eine komplett neue Sprachrichtung, für die parallel gerade die Gesamtübersetzung der Software lief. Nach Tests und Evaluierungen mit dem Anbieter und intern war es spannend, die Performance der spezifischen Systeme im Produktiveinsatz bei uns zu analysieren. Dazu wurde jedes Projekt, das mit der unternehmensspezifischen Engine vorübersetzt wurde, auf den Nachbearbeitungsaufwand und die Anzahl geänderter Segmente hin analysiert. Die Ergebnisse haben sowohl unseren Kunden als auch uns begeistert:
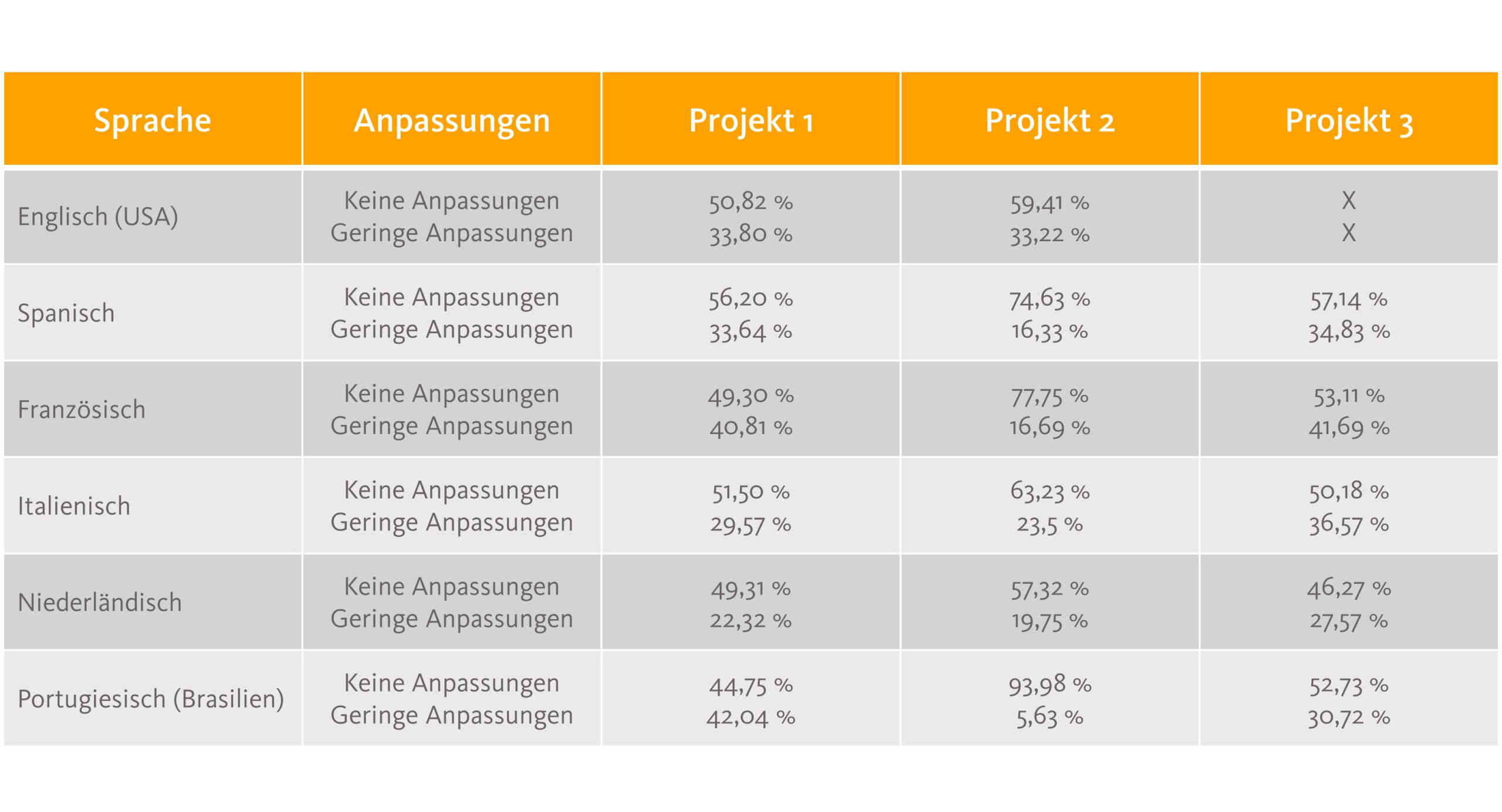
Überblick Customization: Anteil der Segmente aus Kategorie 1 (Keine Anpassungen) und Kategorie 2 (Geringe Anpassungen) pro Zielsprache für drei analysierte Projekte (Quelle: oneword GmbH)
Vor allem Segmente aus Kategorie 1, die unverändert aus der MT übernommen werden können, haben einen wahren Boost erlebt. Der durchschnittliche Wert über alle Sprachen hinweg lag bei 58 Prozent. So muss also über die Hälfte aller Segmente zwar von Posteditor:innen geprüft, aber nicht mehr bearbeitet werden. Eine Tatsache, die auf die oben genannte Anforderung einzahlt, die maschinelle Übersetzung vorübergehend möglichst unbearbeitet zur Verfügung zu stellen. Hinzu kommen je nach Sprache 5 bis 42 Prozent der Segmente, bei denen nur geringe Anpassungen nötig sind. Unterm Strich müssen also je nach Zielsprache und Projekt bis zu 90 Prozent der Segmente nicht oder nur leicht bearbeitet werden. Aus MTPE-Sicht absolute Traumergebnisse!
Doch nicht nur die reinen Zahlen, sondern auch die Möglichkeiten der Fehlerbehebung sprechen für das MT-Training. In einer detaillierten Fehleranalyse konnten wir aufzeigen, welche Fehlerquellen nach dem Training noch bestehen und wie diese kategorisiert werden können. So zeigte sich unter anderem, dass die Verwendung von Tags um GUI-Texte herum (beispielsweise zur Hervorhebung eines Oberflächentexts) immer wieder zu Fehlern führt, weil zu viel, falscher oder zu wenig Text innerhalb der Tags landet. Auch Wörter, deren Wortform in Singular und Plural identisch ist (zum Beispiel Parameter), verursachen erwartungsgemäß Fehler in der Übersetzung. Der klare Vorteil beim MT-Training: Durch den engen Kontakt zum Anbieter lassen sich die gefundenen Fehlerquellen diskutieren und dann eventuell beheben. Während man also bei generischen Systemen (hin-)nehmen muss, was man bekommt, bietet das MT-Training auch nach initialer Bereitstellung des Systems Stellschrauben, um den Output weiter zu verbessern.
Fazit: Übung macht auch weiterhin den Meister
Auch wenn das Training einer oder mehrerer eigenen Engines nach wie vor eine Blackbox ist, konnte unser direkter Vergleich zeigen, dass es sich um einen lohnenden Schritt handeln kann. Die Anforderungen des Unternehmens an das reine MT-Ergebnis und den möglichst geringen Posteditier-Aufwand werden durch sehr gute MT-Ergebnisse erfüllt, sodass auch der reine maschinelle Output vorübergehend verwendet werden kann. Die anfangs erwähnten Features – etwa die Anpassung von Fuzzy Matches – werden durch ein Training mit Daten aus dem Translation Memory hinfällig, da das System aus den vorhandenen Übersetzungen lernt und diese in neuen Texten umsetzt. Zusätzlich zur Terminologie-Integration über das Trainingsmaterial bieten viele Anbieter trainierbarer MT-Systeme auch eine Glossarfunktion, um den MT-Output schneller an sich ändernde Terminologievorgaben anzupassen.
Außerdem lassen sich vorhandene Fehler analysieren und gemeinsam mit dem MT-Anbieter prüfen, wie diese vermieden werden können. Auch hier können teilweise Glossare genutzt werden, um Einzelwörter oder auch spezielle Phrasen zu hinterlegen und deren Umsetzung zu forcieren. Ein weiterer großer Vorteil, der oft übersehen wird: Durch trainierte Engines wird der maschinelle Output im Gegensatz zu generischen Engines reproduzierbar. Während ein Text bei Google Translate, DeepL & Co. nächste Woche aufgrund weiterer Dateninputs vielleicht schon anders übersetzt wird, sind die Ergebnisse nach einer Customization so lange identisch, bis das System durch ein Re-Training an neue Gegebenheiten angepasst wird. Da aber auch trainierte Engines nicht zaubern können, lohnt sich für diese genau wie für generische MT immer auch ein Posteditier-Leitfaden, der für bestehende Fehlerquellen sensibilisiert und Taktiken beinhaltet, um diese möglichst effizient zu beheben.
Möchten Sie mehr über das Training von unternehmensspezifischen Engines, Vergleichsanalysen, die Evaluierung von Fehlern oder die Erstellung von Posteditier-Leitfäden erfahren? Dann nehmen Sie unter mtpe@oneword.de gerne Kontakt mit uns auf.
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.