27.05.2024
Termextraktion und KI: (wie) geht das gut?
Termextraktion ist der erste Schritt zur Gewinnung von Fachterminologie und zur Erstellung einer Terminologiedatenbank. Wie die Extraktion erfolgt, hängt maßgeblich vom Datenbestand und den zeitlichen und personellen Ressourcen ab. Denn Handarbeit stößt bei umfangreichen Ausgangsdateien schnell an ihre Grenzen. Und wo manuelle Aufgaben unterstützt oder automatisiert werden sollen, erfolgt aktuell immer ein Ruf nach KI. Wie sieht es also bei der Termextraktion aus? Reicht es, einen Prompt zu formulieren, um alle Fachtermini aus einem Text herauszuholen? Wir haben Mensch, Maschine und KI in mehreren Tests mit verschiedenen Texten und Prompting-Strategien gegeneinander antreten lassen. Hier stellen wir die Ergebnisse vor und zeigen, welche Vor- und Nachteile jede der drei Optionen mit sich bringt.
Die Vorbereitung: Material und manuelles Referenzergebnis
Was KI für die Texterstellung ist, ist das Schwammstadtkonzept für die Stadtplanung: innovativ und als Buzzword in aller Munde. Passend also, dass wir für unsere Tests zwei Texte zu den Themen Schwammstadt und klimaangepasster Städtebau ausgewählt haben. Beide Texte enthielten eine hohe Terminologiedichte mit Fachtermini aus den Sachgebieten Umwelt, Stadtentwicklung und Klimaanpassung. Um einen möglichen Einfluss des Textumfangs auf die Ergebnisse berücksichtigen zu können, wurden deutlich unterschiedliche Textlängen gewählt: Text 1 umfasste 1.658 Wörter, Text 2 mit 9.803 Wörtern mehr als fünfmal so viel.
Mit zunehmender Textlänge ist eine manuelle Extraktion im Arbeitsalltag eigentlich keine Option: zu aufwändig, zu zeitintensiv, zu teuer. Während Termini aus einem kurzen Text schnell auch manuell erfasst werden können (oder das Anlegen in einer Software sogar aufwändiger wäre), spielt bei längeren Texten neben dem zeitlichen Aufwand auch der Qualitätsaspekt eine Rolle: Ab einer bestimmten Textlänge lässt die Konzentration nach und die Beteiligten werden unsicher, ob sie einen Terminus bereits erfasst haben oder nicht. Dies führt häufig zu mehrfach extrahierten Termini, die zwar am Ende leicht erkannt und eliminiert werden können, während des Extraktionsprozesses aber zusätzlichen Aufwand verursachen.
Gerade im Hinblick darauf, dass auch die Extraktionsergebnisse von Software immer manuell nachgeprüft oder vorgeschlagene Kandidaten validiert werden müssen, gilt das menschliche Ergebnis bei einer Extraktion aber quasi als Goldstandard. Wichtig für unsere Tests war es daher, über vorgelagerte manuelle Extraktionen Referenzwerte zu erhalten, die dann als Messlatte für die Ergebnisse der eingesetzten Tools dienen sollten.
Um diese Messlatte möglichst objektiv zu halten, wurde jede manuelle Extraktion von zwei Personen durchgeführt, die Ergebnisse miteinander verglichen und schließlich zusammengeführt. Aus Text 1 wurden 113 Termini extrahiert, aus Text 2 waren es 299 Termini. Bei einer insgesamt hohen Terminusdichte der Texte deckten sich die Zahlen mit der Praxiserfahrung: In kurzen Fachtexten kommt Terminologie häufig komprimiert vor, während sie sich in längeren Texten häufiger wiederholt.
Die Ergebnisse dienten nicht nur als quantitative Referenz, sondern auch als qualitative: Bei der anschließenden Extraktion durch die Tools sollten nur Termini validiert werden, die auch im manuellen Extraktionsergebnis enthalten waren. Es erfolgte also ein Abgleich der Tool-Ergebnisse gegen die Referenzwerte.
Herausforderer Nummer 1: Extraktionssoftware
Die erste toolgestützte Extraktion erfolgte „klassisch“ mit einer Extraktionssoftware. Dabei wurden für beide Texte mehrere Durchläufe mit unterschiedlichen Einstellungen zum Datenrauschen und der maximalen Terminuslänge durchgeführt.
Im kurzen Text 1 kamen Termini meist nur einmal vor, was mit den Standardeinstellungen zu unzureichenden Ergebnissen führte. Dies zeigte sich auch am Rohergebnis der Extraktion, das je nach Einstellung zwischen 67 und 612 Termini lag. Anschließend erfolgte die manuelle Validierung, um aus den vorgeschlagenen Termkandidaten die tatsächlich relevanten Fachtermini zu erhalten. Beim Durchlauf mit den optimalen Einstellungen führte dies zu einer Validierung von 98 Termini. Das sind 86,73 % des Referenzwerts von 113 Termini aus der manuellen Extraktion.
Auch Text 2 wurde in mehreren Durchläufen mit unterschiedlichen Einstellungen verarbeitet. Mit Rohergebnissen zwischen 538 und 2526 Termini zeigte sich ein deutlich höheres Terminusvorkommen. Im besten Ergebnis wurden 259 der 299 Termini, also 86,62 % des Referenzergebnisses validiert. Je nach vorgenommenen Einstellungen mussten die vorgeschlagenen Termkandidaten sprachlich noch bereinigt werden, beispielsweise um Pluralformen zu Singular zu korrigieren.
Auch wenn bei der Validierung nur ein Abgleich mit dem Referenzergebnis erfolgen sollte, fielen schnell zusätzliche Termini im Rohergebnis auf, die als terminologisch relevant eingestuft wurden. Es erfolgte daher ein weiterer Durchlauf, in dem die Extraktion unabhängig von den manuellen Referenzwerten erfolgte, was zu 30 weiteren validierten Fachtermini führte. Unsere Erklärung: Die Extraktionssoftware liefert das Rohergebnis in Listenform und damit viel konzentrierter als im Gesamttext. Dadurch fallen auch Termini auf, die im Dokument vielleicht überlesen wurden, weil sie in Bildunterschriften oder Fußnoten vorkamen. Die Listenform birgt aber auch das Risiko, dass Termini enthalten sind und validiert werden, die nur Teil eines Firmennamens sind oder im Literaturverzeichnis vorkommen.
Herausforderer Nummer 2: Generative KI
Da der Ruf nach KI-Einsatz auch bei der Termextraktion immer lauter wird, wurden als dritte Option Large Language Models (LLMs) ins Rennen geschickt. Die Frage und Hoffnung dahinter: Kann man Extraktionen mit einer klaren Anweisung in Form eines Prompts und mit wenig Aufwand durchführen und innerhalb von Sekunden bis wenigen Minuten eine Ergebnisliste erhalten?
Bei der Nutzung generativer KI kommt dem Prompting, also der Formulierung der Arbeitsanweisung an das LLM, eine besondere Bedeutung zu. In unseren Tests haben wir daher verschiedene Strategien wie Task-Specific Prompting, Domain-Specific Prompting, Kombinationen aus beiden und auch Reverse Prompting ausprobiert. Bei letzterem zeigt oder beschreibt man dem System das gewünschte Ergebnis und fordert es auf, einen Prompt zu formulieren, der zu diesem Ergebnis führen soll. Insgesamt wurden zehn unterschiedliche Prompts verwendet, die sich in den Anweisungen allgemein und in der Detailliertheit dieser Anweisungen teilweise stark unterschieden. Die besten Prompts wurden mehrmals, also beispielsweise zu unterschiedlichen Zeiten verwendet. Als Large Language Model wurden drei verschiedene Modelle von ChatGPT (GPT-3.5, GPT-4-Turbo, GPT-4o) eingesetzt, da dies aktuell das weitverbreitetste Tool darstellt. Für den Textinput wurde der Text sowohl direkt in das Eingabefenster eingegeben als auch als Datei an das System übergeben.
Bei allen Durchläufen fiel die geringe Anzahl extrahierter Termini auf – besonders in Bezug auf das Referenzergebnis. Beim kürzeren Text 1 lieferte ChatGPT zwischen 20 und 53 Termini als Rohergebnis, von denen zwischen 12 und 35 Termini validiert werden konnten. Damit lag die Abdeckung bezogen auf den Referenzwert bei 30,97 %. Beim längeren Text 2 schlug die KI je nach Prompt zwischen 25 und 157 Termini als Rohergebnis vor, von denen 5 bis maximal 75 validiert wurden. Damit erreichte ChatGPT bei Text 2 eine maximale Abdeckung von nur 25,08 %. Es wurde also nur ein Viertel der Termini erkannt und extrahiert, die ein Mensch im gleichen Text als relevant eingestuft hatte.
Die zehn unterschiedlichen Prompts lieferten große Unterschiede in den Roh- und Endergebnissen, wie unsere folgende Übersicht zu Text 1 zeigt.
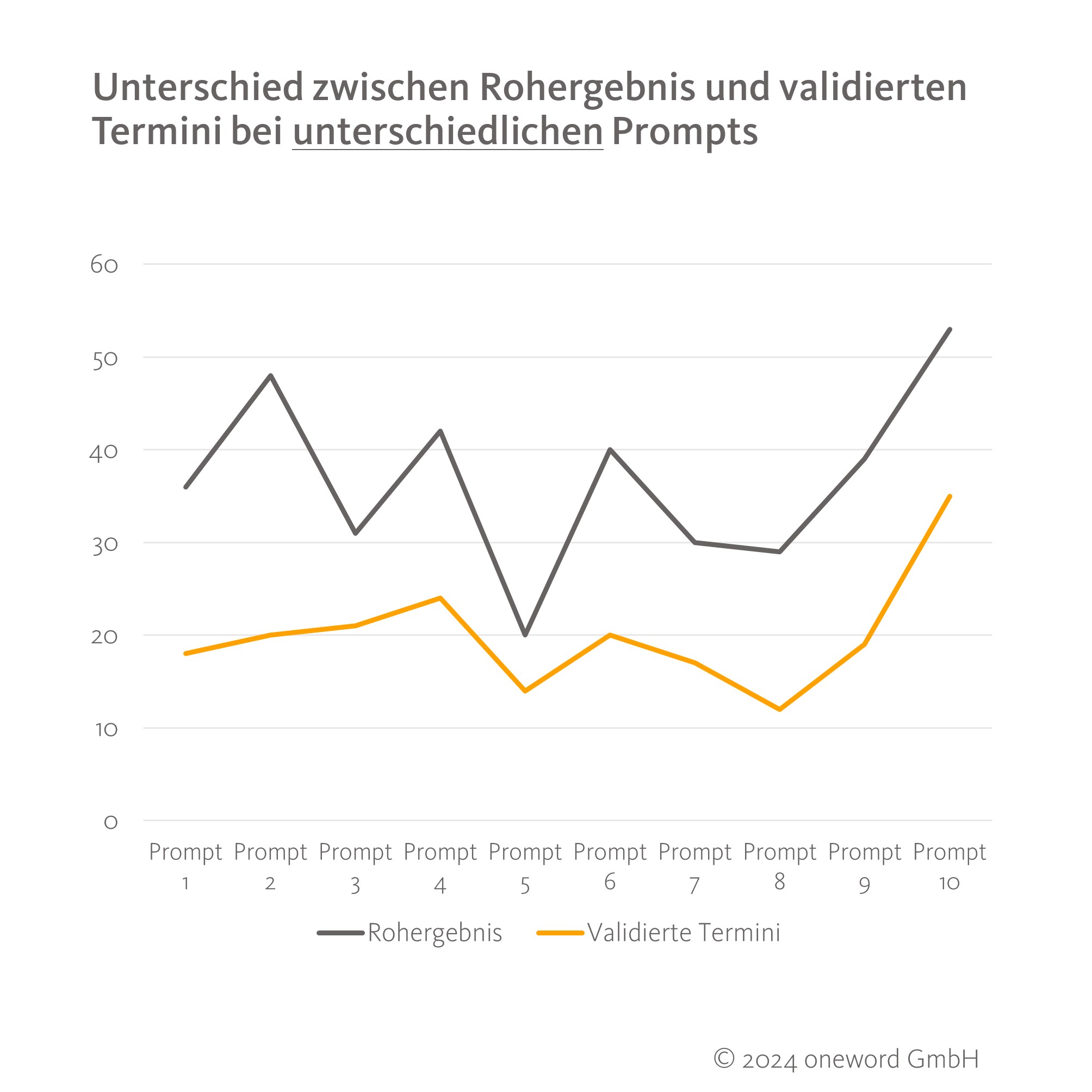
Doch auch identische Prompts lieferten bei identischem Input (gleicher Quelltext, gleiche Form der Dateneingabe) nie zweimal das gleiche Ergebnis, sondern teilweise die dreifache Menge an Termini. Sowohl das Rohergebnis als auch die Menge validierter Termini schwankte, obwohl viermal derselbe Prompt zu unterschiedlichen Zeiten verwendet wurde. Dies zeigt gut die fehlende Reproduzierbarkeit, die beim Einsatz generativer KI aktuell viel diskutiert wird. Außerdem relativiert es den Einfluss der Promptformulierung etwas, da auch der gleiche Input zu sehr unterschiedlichen Ergebnissen führen kann.
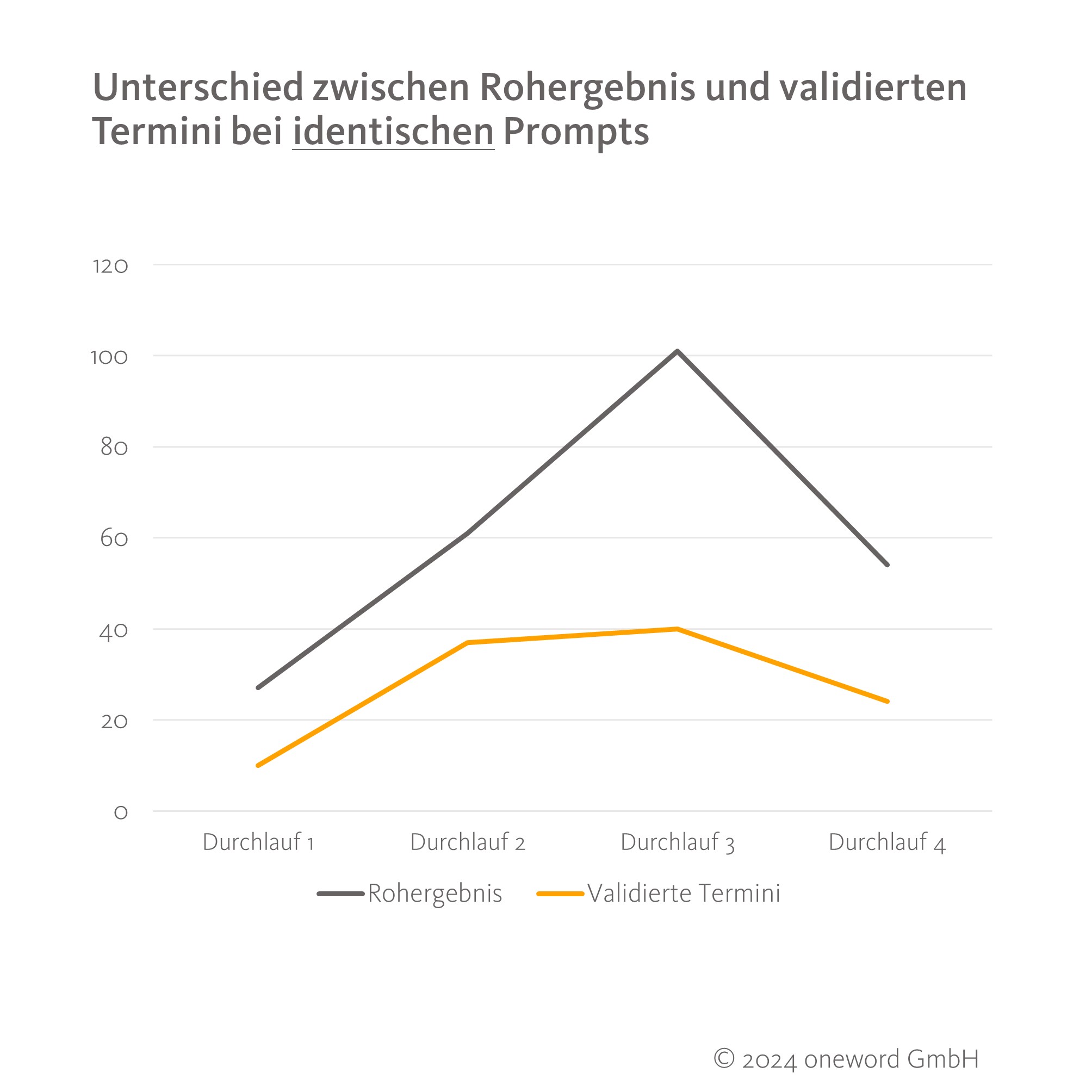
Neben der fehlenden Reproduzierbarkeit begegnete uns bei den Tests eine weitere KI-Schwäche, die die Verlässlichkeit der Ergebnisse einschränkt: Halluzinationen. In insgesamt fünf Durchläufen lieferte ChatGPT Termini, die zwar fachlich korrekt wirkten, aber im Text überhaupt nicht vorkamen. Das neuere Modell ChatGPT4o halluzinierte dabei häufiger als die anderen beiden Modelle.
Da das Ergebnis von ChatGPT deutlich unter dem der anderen Methoden lag, kam die Vermutung auf, dass vielleicht nur hochfrequente Termini von der KI extrahiert werden. In einem weiteren Prompt wurde die Anweisung gegeben, zu jedem Terminus die Vorkommenshäufigkeit im Text anzugeben. Bei gleichem Textinput gab das System beim ersten Versuch eine Frequenz von 2 für den Terminus „Bodenfunktion“ an, beim nächsten Versuch eine Frequenz von 8. Die manuelle Kontrolle ergab, dass der Terminus insgesamt 29-mal im Text vorkam. Auch wenn bekannt ist, dass LLMs keine Rechenmaschinen sind, zeigt sich hier eventuelles Fehlerpotenzial bei der Abfrage zusätzlicher Informationen zum Extraktionsergebnis. Nach weiteren Analysen konnte nicht bestätigt werden, dass die von der KI extrahierten Termini häufiger als andere, nicht extrahierte Termini in den Texten vorkamen.
Der Zieleinlauf – und was es zu beachten gilt
Je nach eingesetzter Methode kann eine Termextraktion, wie gezeigt, zu sehr unterschiedlichen Ergebnissen führen. Doch nur das Endergebnis allein kann keine Entscheidungsgrundlage sein, da im Arbeitsalltag neben der Anzahl der extrahierten Termini immer auch die Zeit und Kosten sowie mögliches Fehlerpotenzial und Prozessrisiken betrachtet werden müssen.
In unseren Tests wurde die Dauer der Extraktion pro Methode dokumentiert. Diese hängt allerdings in allen Fällen davon ab, wie routiniert man mit den Aufgaben oder dem jeweiligen Tool umgeht und im Falle von ChatGPT auch, ob ein Prompt erst noch formuliert und getestet werden muss oder ob auf einen bereits erprobten Prompt zurückgegriffen wird.
Für den längeren Text 2 (9.803 Wörter) fiel der Zeitvergleich sehr deutlich aus:
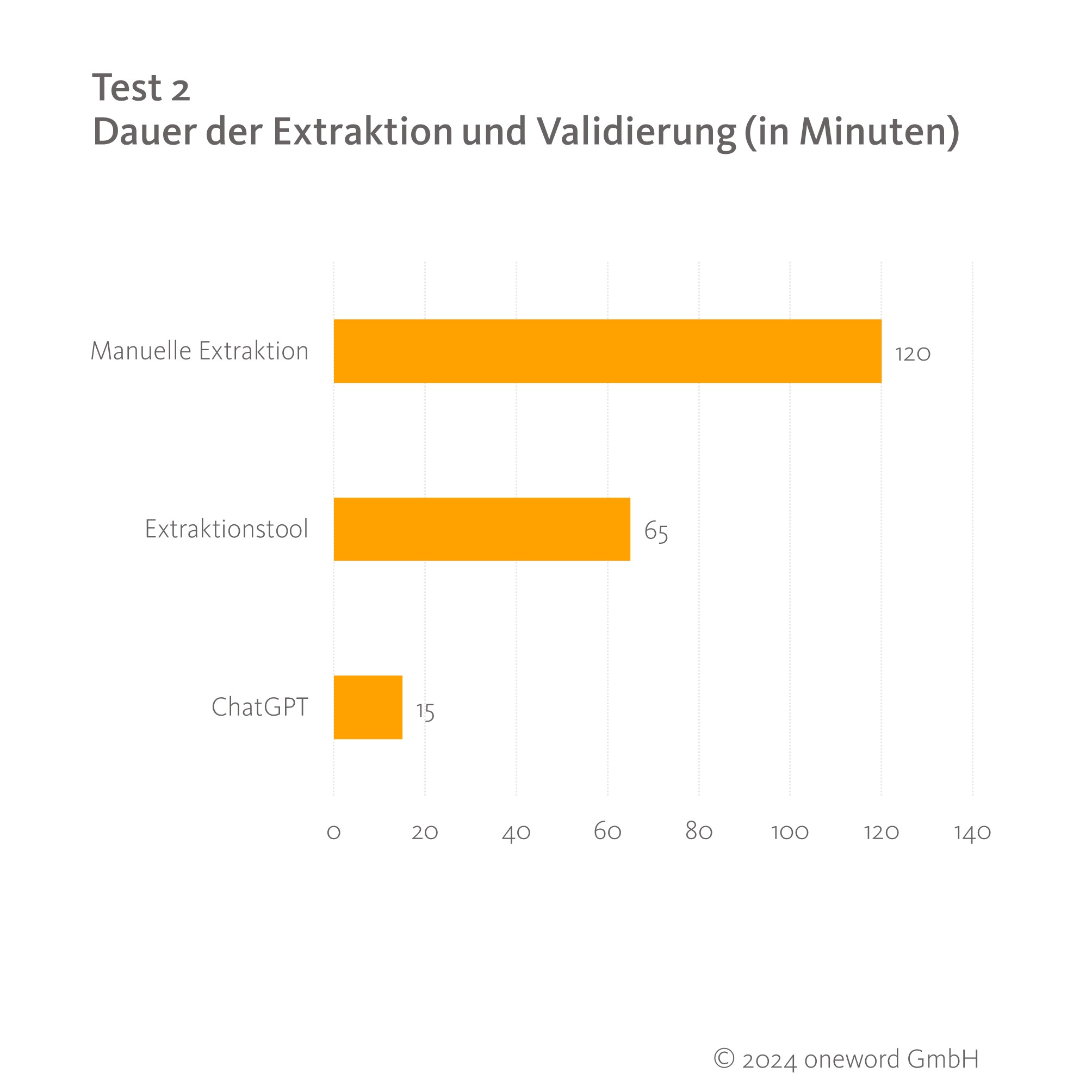
Während der Einsatz einer Extraktionssoftware immerhin fast die Hälfte der Zeit einer manuellen Extraktion einspart, ist ChatGPT hier mit nur einem Achtel der benötigten Zeit die ungeschlagen schnellste Methode. Das Formulieren und Eingeben eines Prompts erfolgen deutlich schneller als das Anlegen eines Extraktionsprojekts im Tool oder die Durchsicht mehrerer Seiten eines Dokuments. Auch die Verarbeitung und Ausgabe der Ergebnisse ist mit ChatGPT innerhalb weniger Sekunden abgeschlossen. Die erhaltenen Ergebnisse waren durchweg terminologisch sauber und hätten zumindest aus sprachlicher Sicht ohne Nachbearbeitung weiterverwendet werden können. Sowohl bei der manuellen als auch bei der softwaregestützten Extraktion mussten Termini hingegen oft noch in die Grundform gebracht verwenden.
Der Einsatz von ChatGPT für die Termextraktion hat außerdem den Vorteil, dass das Ergebnis bereits in unterschiedlicher Darstellungsweise (z. B. als Liste, in Spalten etc.) oder Dateiformaten (z. B. Excel) angefordert werden kann, um es optimal weiterverarbeiten zu können. Damit sind Prozessautomatisierungen zum direkten Befüllen einer Datenbank auf Basis der Extraktionsergebnisse möglich. Und was Zeit spart, spart im Arbeitskontext entsprechend auch Kosten.
Gerade Zeit, Aufwand und Kosten sind auch die Gründe, weshalb eine manuelle Extraktion, die in unseren Tests als wichtige Benchmark galt, im Arbeitsalltag meist keine realistische Option darstellt. Denn Termextraktionen kommen vor allem bei großen Textmengen zum Einsatz. Der deutlich höhere Aufwand rein menschlicher Arbeit steht in diesen Fällen dann in keinem Verhältnis zur größeren Terminusmenge, die damit gefunden werden könnte.
Obwohl das manuelle Ergebnis auch qualitativ als Messlatte galt, ist natürlich auch beim Faktor Mensch Fehlerpotenzial vorhanden. Neben den zusätzlichen Termini, die wie oben erwähnt bei der toolbasierten Extraktion noch validiert wurden und der Fehleranfälligkeit aufgrund schwindender Konzentration bei großen Textmengen, spielt vor allem die Subjektivität bei der Extraktion eine große Rolle. Zwei Terminolog:innen werden wahrscheinlich nie das exakt gleiche Ergebnis einer Validierung liefern, weil es immer auch Graubereiche gibt, welche Wörter wirklich als Fachtermini angesehen werden. Zusätzlich beeinflussen unterschiedliche Validierungsstrategien das Ergebnis: Je nachdem, wie weit man ein Sachgebiet fasst, wird man mehr oder weniger Termini validieren. In unserem Beispiel ist das allgemeine Sachgebiet „Umwelt und Klima“, das spezifische Sachgebiet „klimaangepasste Stadtplanung“. Nur letzteres zu betrachten, führt zu deutlich weniger Validierungen als die Einbeziehung des allgemeinen Sachgebiets. Wir haben in unserem Test versucht, diese Subjektivität und Beeinflussung durch den Vergleich der Ergebnisse von zwei Terminolog:innen und durch Absprachen und Vorgaben zu relativieren.
Fazit: Viele Wege führen zur Termextraktion
Die drei untersuchten Methoden zur Termextraktion zeigen zwar deutliche Unterschiede, können aber in verschiedenen Anwendungsfällen alle nützlich sein. Manuelle Extraktion als Goldstandard ist in der Theorie zwar der Klassenbeste, scheitert im Unternehmensalltag aber oftmals schlichtweg an der Umsetzbarkeit und ist wie gezeigt auch nicht unfehlbar.
KI liefert sehr schnelle, aber mitunter auch falsche Ergebnisse, die – wie alles, was direkt aus der Maschine kommt – kritisch geprüft werden müssen. Die deutlich geringere Terminusanzahl spricht gegen den Einsatz bei einem umfangreichen Extraktionsprojekt oder beim Wunsch nach einem umfassenden Terminologieaufbau. Die Schnelligkeit und Automatisierbarkeit des Prozesses ermöglicht aber einen Terminologieaufbau „on the fly“, bei dem ohne viel Aufwand nach und nach ein Bestand aufgebaut werden kann. Kritisch zu sehen sind die von der KI erfundenen Termini, die sich in die Datenbank einschleichen, sowie die fehlende Reproduzierbarkeit durch unterschiedliche Ergebnisse bei exakt gleichem Input.
Auf Termextraktion spezialisierte Software stellte sich im Test als der optimale Mittelweg heraus. Die Lösung ist im Alltag der Terminologiearbeit der Standard und sicherlich immer eine gute Wahl. In unseren Vergleichen erreichte die Software bei geringerem zeitlichen Aufwand gute Ergebnisse oder übertraf den Referenzwert sogar. Wichtig beim Einsatz der Tools sind die für jedes Projekt passenden Einstellungen, um die Ausbeute zu erhöhen und den Aufwand für die Nacharbeit zu reduzieren.
Termini lassen sich also auf unterschiedlichen Wegen und mit unterschiedlichen Ergebnissen extrahieren. Entscheidend ist daher eher die Frage, was erreicht werden soll und wie viele Ressourcen dafür eingesetzt werden können. Am Ende geht aber auch die Termextraktion nur mit dem „human in the loop“, denn es bleibt am Menschen, die Rohergebnisse aus Software oder KI zu prüfen und zu validieren.
Möchten Sie mehr über Termextraktion erfahren oder einen Terminologiebestand auf Grundlage Ihrer Daten aufbauen? Dann steht Ihnen unser Terminologie-Team gern zur Verfügung: terminologie@oneword.de
8 gute Gründe für oneword.
Erfahren Sie mehr über unsere Kompetenzen und was uns von klassischen Übersetzungsagenturen unterscheidet.
Wir liefern Ihnen 8 gute Gründe und noch viele weitere Argumente, warum eine Zusammenarbeit mit uns erfolgreich ist.